The step-13 tutorial program
In a Soft Sphere system the interactions between two particles are spatially bounded.
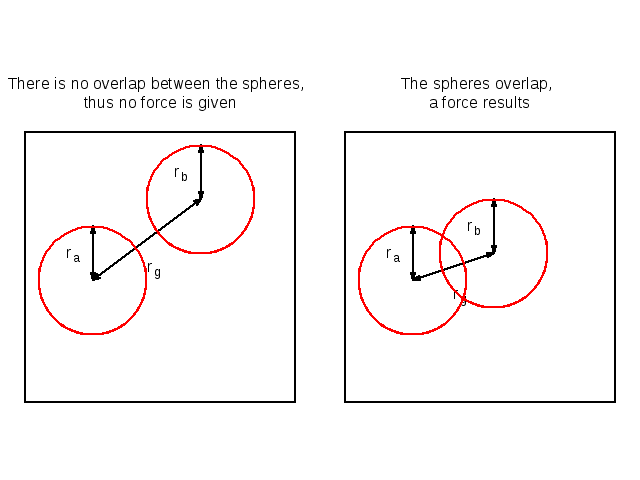
Collision scheme
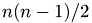 pair interactions where
pair interactions where 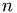 is the number of particles, the system is spatially divided in subsystems.
is the number of particles, the system is spatially divided in subsystems. 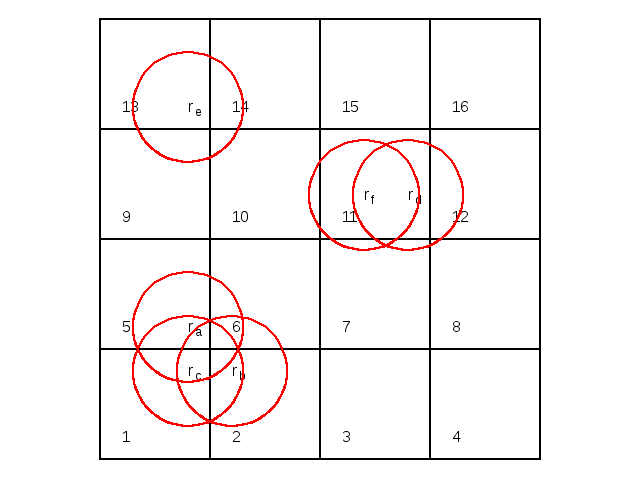
Spatial subdivison
To make use of the subdivision for each particle a thread calculates in which cell the particle is in at first. The cells are identified by CellIDs. After that an array of the size of the number of particles is given and an entry 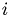 at index
at index 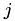 means that the center of particle number is located at the cell with CellID . Thus one can easily check which particle is in wich cell. Nevertheless the interest lies in an easy check which cell contain which particles. A fast (parallel) Radix sort algorithm is able to serve an answer to this task. If the information is given which cell contain which particles, beginning at a certain particle a simple loop over neighbouring cells will be easy to perform in order to sum the pair forces. Here a thread is assigned to each particle, too. With the knowledge of the forces the equation of motion can be integrated (again one thread per particle).
means that the center of particle number is located at the cell with CellID . Thus one can easily check which particle is in wich cell. Nevertheless the interest lies in an easy check which cell contain which particles. A fast (parallel) Radix sort algorithm is able to serve an answer to this task. If the information is given which cell contain which particles, beginning at a certain particle a simple loop over neighbouring cells will be easy to perform in order to sum the pair forces. Here a thread is assigned to each particle, too. With the knowledge of the forces the equation of motion can be integrated (again one thread per particle).
If a normal force is given by
![\[ F = Y\xi + \gamma\dot{\xi}, \]](form_205.png)
where
![\[ \xi = R_a + R_b - \| r_a - r_b \| \]](form_206.png)
is the overlap between the particles 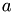 and
and 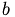 with radii
with radii 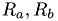 and positions
and positions 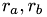 one possible check for the correctness will be the proof of Haffs law. Haffs law states that given an initial temperature
one possible check for the correctness will be the proof of Haffs law. Haffs law states that given an initial temperature 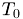 the system will cool down according to
the system will cool down according to
![\[ T(t) \propto \frac{T_0}{(1+\frac{\epsilon}{2dt_0}t)^2}, \]](form_211.png)
where 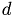 is the diameter of the particles,
is the diameter of the particles, 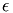 is the coefficient of restitution
is the coefficient of restitution
![\[ \epsilon = \exp{\left (-\frac{\pi \gamma}{m \sqrt{2Y/m-(\gamma/m)^2}} \right )}, \]](form_214.png)
and 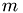 is the mass of the particles.
is the mass of the particles.
Different schemes for solving the equation of motions are implemented. The first one is an explicit Euler scheme which is easy to implement and shows with small step size appropriate results with an adequate spped. The advantage of the Euler scheme could be that the amount of storage is 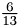 of the amount of the Gear scheme which is implemented too. This is a predictor—corrector method and does not require a step size as is required by euler. *
of the amount of the Gear scheme which is implemented too. This is a predictor—corrector method and does not require a step size as is required by euler. *
The commented program
#ifndef CUDA_KERNEL_STEP_13_CU_H #define CUDA_KERNEL_STEP_13_CU_H #include <iostream> #include <cutil_inline.h>
Basic Definitions and Parameters
Enumerators for different tasks. The names are self explanatory.
enum particleconfig {rnd, conf}; enum boundary {periodic, lees_edwards}; enum solver {euler, gear}; struct ParticleTypeSpecs{ ParticleTypeSpecs(int NumberOfSpecies); void Reinit(int NumberOfSpecies); ParticleTypeSpecs() {} ~ParticleTypeSpecs(); int NSpecies; unsigned int *Number; float *Mass; float *Radius; };
Struct that contains the physical properties and the solver
struct BasicParamsType { BasicParamsType() {} particleconfig PConf; boundary boundary_conditions; solver SolverType; float SystemSizeX; float SystemSizeY; unsigned int NumberParticles; float Time; float TimeStep; unsigned int Seed; unsigned int measure; const char* fileout; };
Declaration of the Kernel Wrapper Functions
The following functions are called by methods of a member of the class Particles. These functions use data from the device, call kernels or in case of 'sort'
inline void cuda_check_errors(const char* filename, int line); void h_calcid(const float2 *pos, unsigned int *CellId, unsigned int *PId, const BasicParamsType dev_BasicParams, unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid); void sort(unsigned int *CellId, unsigned int *PId, unsigned int NumberParticles); void h_reorder(unsigned int *CellStart, unsigned int *CellEnd, float2 *inPos, float2 *outPos, float2 *inVel, float2 *outVel, float2* inForce, float2* outForce, float2* inr3dot, float2* outr3dot, float2* inr4dot , float2* outr4dot, float2* inr5dot, float2* outr5dot, unsigned int* inParticleType, unsigned int* outParticleType, unsigned int *CellId, unsigned int *PId, const BasicParamsType &BasicParams, unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid); void h_force(const float2* Pos, const float2* Vel, float2* Force, const unsigned int* CellStart, const unsigned int* CellEnd, const float2* R, const unsigned int* ParticleType, BasicParamsType BasicParams, unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid); inline void cuda_check_errors(const char* filename, int line) { #ifdef DEBUG cudaThreadSynchronize(); cudaError_t error = cudaGetLastError(); if(error != cudaSuccess) { printf("CUDA error at %s:%d: %s", filename, line, cudaGetErrorString(error)); exit(-1); } #endif }
Functions to compute the number of cells
unsigned int calc_NumberOfCellsX(float SystemSizeX); unsigned int calc_NumberOfCellsY(float SystemSizeY); unsigned int calc_NumberOfCells(unsigned int NumberOfCellsX,unsigned int NumberOfCellsY); template <solver s, boundary b> struct StepperScheme { static const solver SolverType=s; static const boundary BoundaryType=b; static void h_integrate(float2* Pos, float2* Vel, float2* Force, float2* r3dot, float2* r4dot, float2* r5dot, float2* Force_predict, const unsigned int *CellStart, const unsigned int *CellEnd, const float2* R, const unsigned int* ParticleType, const BasicParamsType &BasicParams, float2* host_Pos, float2* host_Vel, float2* host_Force, int flag, unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid, float time); }; #endif // CUDA_KERNEL_STEP_13_CU_H #include <cutil_inline.h> #include <cuda_kernel_wrapper_step-13.cu.h> #include "integration_step-13.h" #include "integration_step-13.cu.c"
Global functions
Here the kernels are called. Every kernel is called by a method of a member of the class Particles
Function: h_calcid
The kernel calcid computes for every particle wich cell it is in (the CellId).
void h_calcid(const float2 *pos, unsigned int *CellId, unsigned int *PId, const BasicParamsType BasicParams, unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid) { dim3 grid(BlocksPerGrid); dim3 blocks(ThreadsPerBlock); calcid<<<grid, blocks>>>(pos, CellId, PId, BasicParams); cuda_check_errors(__FILE__, __LINE__); }
Function: h_reorder
After sorting the particles with respect to their CellIds (which means that the PId does not coincide with the 'array-index' in general) the kernel reorder sorts the corresponding positions, velocities and higher oder derivatives with respect to the corresponding PIds
- Parameters:
-
CellStart : This array contains in entry ![$CellStart[index]$](form_217.png) the information how many particles reside in the cells with
the information how many particles reside in the cells with ![$CellId < CellStart[index]$](form_218.png)
CellEnd : This array contains in entry ![$CellEnd[index]$](form_219.png) the information how many particles reside in the cells with
the information how many particles reside in the cells with ![$CellId \leq CellStart[index]$](form_220.png)
inPos : the unsorted positions outPos : the sorted positions inVel : the unsorted velocities outVel : the sorted velocities inForce : the unsorted forces outForce : the sorted forces inr3dot : the unsorted third order derivatives outr3dot : the sorted third order derivatives inr4dot : the unsorted fourth order derivatives outr4dot : the sorted fourth order derivatives inr5dot : the unsorted fifth order derivatives outr5dot : the sorted fifth order derivatives CellId : a partice with @ PId[index] resides in CellId[index]PId : numbers the particles BasicParams : basic parameter for the simulation ThreadsPerBlock : threads per block BlocksPerGrid : blocks per grid
void h_reorder(unsigned int *CellStart, unsigned int *CellEnd, float2 *inPos, float2 *outPos, float2 *inVel, float2 *outVel, float2* inForce, float2* outForce, float2* inr3dot, float2* outr3dot, float2* inr4dot , float2* outr4dot, float2* inr5dot, float2* outr5dot, unsigned int* inParticleType, unsigned int* outParticleType, unsigned int *CellId, unsigned int *PId, const BasicParamsType &BasicParams, unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid) { dim3 grid(BlocksPerGrid); dim3 blocks(ThreadsPerBlock);
Ns specifies the number of bytes in shared memory that is dynamically allocated per block. The data type is unsigned int. Each block has size (blocks.x+1)*blocks.y*blocks.z. block.x+1 is caused by the additional component of the array for the commuication between the blocks.
size_t Ns = sizeof(unsigned int)*(blocks.x+1);
0xffffffff corresponds to -1 and marks that in the given cell no particle resides.
cutilSafeCall(cudaMemset((void *)CellStart, 0xffffffff, sizeof(unsigned int)* calc_NumberOfCells( calc_NumberOfCellsX(BasicParams.SystemSizeX), calc_NumberOfCellsY(BasicParams.SystemSizeY)))); reorder<<<grid, blocks, Ns>>>(CellStart, CellEnd, inPos, outPos, inVel, outVel, inForce, outForce, inr3dot, outr3dot, inr4dot, outr4dot, inr5dot, outr5dot, inParticleType, outParticleType, CellId, PId, BasicParams.NumberParticles); cuda_check_errors(__FILE__, __LINE__); }
Function: h_force
The kernel force is called by the chosen integration scheme and uses the information about velocities and positions to sum up all contributing pair forces for each particles. The parameter CellStart and CellEnd indicate the number of particles residing in the Cells
- Parameters:
-
Pos : the positions Vel : the velocities Force : the forces CellStart : This array contains in entry the information how many particles reside in the cells with CellEnd : This array contains in entry the information how many particles reside in the cells with BasicParams : basic parameter for the simulation ThreadsPerBlock : threads per block BlocksPerGrid : blocks per grid
void h_force(const float2* Pos, const float2* Vel, float2* Force, const unsigned int* CellStart, const unsigned int* CellEnd, const float2* R, const unsigned int* ParticleType, BasicParamsType BasicParams, unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid) { dim3 grid(BlocksPerGrid); dim3 blocks(ThreadsPerBlock); force<<<grid, blocks>>>(Pos, Vel, Force, CellStart, CellEnd, R, ParticleType, BasicParams); cuda_check_errors(__FILE__, __LINE__); }
Function: h_integrate
The funktion h_integrate which calls the kernels integrate, force (and predict) makes use of templates. Now the template parameter is the solver scheme
Template struct; here the types of the solvers are written
template <solver s, boundary b> struct StepperTraits;
Euler integration, periodic boundary conditions
template <> struct StepperTraits<euler, periodic> { typedef Euler<Pbc> SolverType; typedef Pbc BoundaryType; };
Euler integration, lees-edwards conditions
template <> struct StepperTraits<euler, lees_edwards> { typedef Euler<LeesEdwards> SolverType; typedef LeesEdwards BoundaryType; };
Gear integration, periodic boundary conditions
template <> struct StepperTraits<gear, periodic> { typedef Gear<Pbc> SolverType; typedef Pbc BoundaryType; };
Gear integration, periodic boundary conditions
template <> struct StepperTraits<gear, lees_edwards> { typedef Gear<LeesEdwards> SolverType; typedef LeesEdwards BoundaryType; }; template <solver s, boundary b> void _integrate(float2* Pos, float2* Vel, float2* Force, float2* r3dot, float2* r4dot, float2* r5dot, float2* Force_predict, const unsigned int* CellStart, const unsigned int* CellEnd, const float2* R, const unsigned int* ParticleType, const BasicParamsType &BasicParams, float2* host_Pos, float2* host_Vel, float2* host_Force, int flag, unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid, float time) { dim3 grid(BlocksPerGrid); dim3 blocks(ThreadsPerBlock); cudaThreadSynchronize(); if (flag == 0) { cudaMemcpy((void *)host_Pos,(void *)Pos, BasicParams.NumberParticles*sizeof(float2), cudaMemcpyDeviceToHost); cudaMemcpy((void *)host_Vel,(void *)Vel, BasicParams.NumberParticles*sizeof(float2), cudaMemcpyDeviceToHost); cudaMemcpy((void *)host_Force,(void *)Force, BasicParams.NumberParticles*sizeof(float2), cudaMemcpyDeviceToHost); } integrate<typename StepperTraits<s, b>::SolverType, typename StepperTraits<s, b>::BoundaryType><<<grid, blocks>>>(Pos, Vel, Force, r3dot, r4dot, r5dot, Force_predict, CellStart, CellEnd, BasicParams, time); cuda_check_errors(__FILE__, __LINE__); } template <solver s, boundary b> void _predict(float2* Pos, float2* Vel, float2* Force, float2* r3dot, float2* r4dot, float2* r5dot, float2* Force_predict, const BasicParamsType &BasicParams, unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid, float time) { dim3 grid(BlocksPerGrid); dim3 blocks(ThreadsPerBlock); typedef typename StepperTraits<s, b>::SolverType SolverType; typedef typename StepperTraits<s, b>::BoundaryType BoundaryType; predict<SolverType, BoundaryType><<<grid, blocks>>> (Pos, Vel, Force, r3dot, r4dot, r5dot, Force_predict, BasicParams, time); cuda_check_errors(__FILE__, __LINE__); }
Specialized function for euler with pbc
template <> void StepperScheme<euler, periodic>::h_integrate(float2* Pos, float2* Vel, float2* Force, float2* r3dot, float2* r4dot, float2* r5dot, float2* Force_predict, const unsigned int* CellStart, const unsigned int* CellEnd, const float2* R, const unsigned int* ParticleType, const BasicParamsType &BasicParams, float2* host_Pos, float2* host_Vel, float2* host_Force, int flag, unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid, float time) { h_force(Pos, Vel, Force, CellStart, CellEnd, R, ParticleType, BasicParams, ThreadsPerBlock, BlocksPerGrid); _integrate<euler, periodic>(Pos, Vel, Force, r3dot, r4dot, r5dot, Force_predict, CellStart, CellEnd, R, ParticleType, BasicParams, host_Pos, host_Vel, host_Force, flag, ThreadsPerBlock, BlocksPerGrid, time); cuda_check_errors(__FILE__, __LINE__); }
Specialized function for gear with pbc. Notice the order: prediction, force computation, correction/integration
template <> void StepperScheme<gear, periodic>::h_integrate(float2* Pos, float2* Vel, float2* Force, float2* r3dot, float2* r4dot, float2* r5dot, float2* Force_predict, const unsigned int* CellStart, const unsigned int* CellEnd, const float2* R, const unsigned int* ParticleType, const BasicParamsType &BasicParams, float2* host_Pos, float2* host_Vel, float2* host_Force, int flag, unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid, float time) { _predict<gear, periodic>(Pos, Vel, Force, r3dot, r4dot, r5dot, Force_predict, BasicParams, ThreadsPerBlock, BlocksPerGrid, time); cudaThreadSynchronize(); h_force(Pos, Vel, Force, CellStart, CellEnd, R, ParticleType, BasicParams, ThreadsPerBlock, BlocksPerGrid); _integrate<gear, periodic>(Pos, Vel, Force, r3dot, r4dot, r5dot, Force_predict, CellStart, CellEnd, R, ParticleType, BasicParams, host_Pos, host_Vel, host_Force, flag, ThreadsPerBlock, BlocksPerGrid, time); cuda_check_errors(__FILE__, __LINE__); }
Specialized function for euler with la
template <> void StepperScheme<euler, lees_edwards>::h_integrate(float2* Pos, float2* Vel, float2* Force, float2* r3dot, float2* r4dot, float2* r5dot, float2* Force_predict, const unsigned int* CellStart, const unsigned int* CellEnd, const float2* R, const unsigned int* ParticleType, const BasicParamsType &BasicParams, float2* host_Pos, float2* host_Vel, float2* host_Force, int flag, unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid, float time) { h_force(Pos, Vel, Force, CellStart, CellEnd, R, ParticleType, BasicParams, ThreadsPerBlock, BlocksPerGrid); _integrate<euler, lees_edwards>(Pos, Vel, Force, r3dot, r4dot, r5dot, Force_predict, CellStart, CellEnd, R, ParticleType, BasicParams, host_Pos, host_Vel, host_Force, flag, ThreadsPerBlock, BlocksPerGrid, time); cuda_check_errors(__FILE__, __LINE__); }
Specialized function for gear with la. Notice the order: prediction, force computation, correction/integration
template <> void StepperScheme<gear, lees_edwards>::h_integrate(float2* Pos, float2* Vel, float2* Force, float2* r3dot, float2* r4dot, float2* r5dot, float2* Force_predict, const unsigned int* CellStart, const unsigned int* CellEnd, const float2* R, const unsigned int* ParticleType, const BasicParamsType &BasicParams, float2* host_Pos, float2* host_Vel, float2* host_Force, int flag, unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid, float time) { _predict<gear, lees_edwards>(Pos, Vel, Force, r3dot, r4dot, r5dot, Force_predict, BasicParams, ThreadsPerBlock, BlocksPerGrid, time); cudaThreadSynchronize(); h_force(Pos, Vel, Force, CellStart, CellEnd, R, ParticleType, BasicParams, ThreadsPerBlock, BlocksPerGrid); _integrate<gear, lees_edwards>(Pos, Vel, Force, r3dot, r4dot, r5dot, Force_predict, CellStart, CellEnd, R, ParticleType, BasicParams, host_Pos, host_Vel, host_Force, flag, ThreadsPerBlock, BlocksPerGrid, time); cuda_check_errors(__FILE__, __LINE__); } #ifndef MDSolver_STEP_13_H #define MDSolver_STEP_13_H #include <cutil_inline.h>
Maps are used to connect input strings with enumerators
#include <map> #include "cuda_kernel_wrapper_step-13.cu.h" #include <QString> #include <QRegExp>
DEALII for parameter input
#include <base/parameter_handler.h>
Parameter handling and user interface
the following lines implement the inpu of parameters as well as the handling of technical parameters that are important for the simulation
namespace step13 {
Struct: SimulationParams
SimulationParams contains the BasicParams and is responsible for the parameter handling with dealii
struct SimulationParams : public BasicParamsType {
String that contains the output filename std::string ParticlesType; Declares the variables to read in by the ParameterHandler
static void declare(::ParameterHandler &prm);
Reads the Parameters
void get(:: ParameterHandler &prm); ParticleTypeSpecs ParticleSpecs; };
Defines the parameter input file
void SimulationParams::declare(::ParameterHandler &prm) { prm.declare_entry("Configuration", "rnd", ::Patterns::Anything(), "Specifies the CONF" ); prm.declare_entry("Boundary Condition", "periodic", ::Patterns::Anything(), "Specifies the BC" ); prm.declare_entry("Solver", "euler", ::Patterns::Anything(), "Specifies the Solver" ); prm.declare_entry("SystemSizeX", "16", ::Patterns::Double(), "Specifies the SystemSize in x-direction" ); prm.declare_entry("SystemSizeY", "16", ::Patterns::Double(), "Specifies the SystemSize in y-direction" ); prm.declare_entry("Time", "2.0", ::Patterns::Double(), "Specifies the desired simulation time" ); prm.declare_entry("TimeStep", "0.1", ::Patterns::Double(), "Specifies the time-step" ); prm.declare_entry("Seed", "1", ::Patterns::Integer(), "Specifies the seed for the PRNG" ); prm.declare_entry("Measure", "10", ::Patterns::Integer(), "Specifies the number of timesteps between measurements" ); prm.declare_entry("Fileout", "output", ::Patterns::Anything(), "Specifies the name of an outputfile: output_measured-timestep.dat; write \"none\" for no output" ); prm.declare_entry("ParticlesType", "<N=1000,r=0.5,m=1>", ::Patterns::Anything(), "Specifies the parameters of the particles" ); }
Construct map between cstrings and enumerators in order to read the prm-file. The input strings for the configuaration, boundary conditions and the solver are mapped to the corresponding enumerators.
void SimulationParams::get(::ParameterHandler &prm) { typedef std::map<std::string, particleconfig> PC_NAME2ENUM; PC_NAME2ENUM pc_name2enum; pc_name2enum["rnd"]=rnd; pc_name2enum["conf"]=conf; PC_NAME2ENUM::const_iterator pc = pc_name2enum.find(prm.get("Configuration")); if (pc != pc_name2enum.end()) PConf = pc->second; else { std::cerr << "Illegal value for Particle Configuration. Check prm-file" << std::endl; exit(-1); } typedef std::map<std::string, boundary> BC_NAME2ENUM; BC_NAME2ENUM bc_name2enum; bc_name2enum["periodic"]=periodic; bc_name2enum["lees_edwards"]=lees_edwards; BC_NAME2ENUM::const_iterator bc = bc_name2enum.find(prm.get("Boundary Condition")); if (bc != bc_name2enum.end()) this->boundary_conditions = bc->second; else { std::cerr << "Illegal value for Boundary Condition. Check prm-file" << std::endl; exit(-1); } typedef std::map<std::string, solver> S_NAME2ENUM; S_NAME2ENUM s_name2enum; s_name2enum["euler"]=euler; s_name2enum["gear"]=gear; S_NAME2ENUM::const_iterator s = s_name2enum.find(prm.get("Solver")); if (s != s_name2enum.end()) SolverType = s->second; else { std::cerr << "Illegal value for Solver. Check prm-file" << std::endl; exit(-1); }
The numerical values of the other parameters are simply read in.
SystemSizeX = prm.get_double("SystemSizeX"); SystemSizeY = prm.get_double("SystemSizeY"); Time = prm.get_double("Time"); TimeStep = prm.get_double("TimeStep"); Seed = prm.get_integer("Seed"); measure = prm.get_integer("Measure"); fileout = prm.get("Fileout").c_str(); QString Q_ParticlesType(prm.get("ParticlesType").c_str()); QRegExp Q_ParticlesSeperator(">\\s*<"); unsigned int NumberOfSpecies = Q_ParticlesType.count(Q_ParticlesSeperator) + 1;
printf("%d arten\n",NumberofSpecies); std::cout << Q_ParticlesType.toStdString() << std::endl;
Use regular expression: example Q_GetRadius: the first letters are 'r=' followed by any number and possibly a dot '.'. after the dot further numbers are allowed Q_GetFloat receives a parameter (that name is defined by one letter at least) and a equal-sign '=' followed by the number
QRegExp Q_GetRadius("r=[0-9]*\\x002E{0,1}[0-9]*"); QRegExp Q_GetMass("m=[0-9]*\\x002E{0,1}[0-9]*"); QRegExp Q_GetNumber("N=[0-9]*"); QRegExp Q_GetFloat("(.{1,}=)([0-9]*\\x002E{0,1}[0-9]*)"); QRegExp Q_GetInt("(.{1,}=)([0-9]*)"); if (NumberOfSpecies == 0) { printf("Error: a simulation without particles?"); exit(-1); } else { ParticleSpecs.Reinit(NumberOfSpecies); for (unsigned int zaehler=0; zaehler<NumberOfSpecies; zaehler++) {
sucht die durch zaehler indizierte section und gibt das darin enthaltende entsprechende muster aus
int posN1 = Q_GetNumber.indexIn(Q_ParticlesType.section(Q_ParticlesSeperator, zaehler, zaehler, QString::SectionSkipEmpty)); int posN2 = Q_GetInt.indexIn(Q_GetNumber.cap(0));
std::cout << Q_GetInt.cap(2).toStdString() << std::endl;
ParticleSpecs.Number[zaehler] = Q_GetInt.cap(2).toInt();
int posR1 = Q_GetRadius.indexIn(Q_ParticlesType.section(Q_ParticlesSeperator, zaehler, zaehler, QString::SectionSkipEmpty));
int posR2 = Q_GetFloat.indexIn(Q_GetRadius.cap(0));
std::cout << Q_GetFloat.cap(2).toStdString() << std::endl;
ParticleSpecs.Radius[zaehler] = Q_GetFloat.cap(2).toFloat();
int posM1 = Q_GetMass.indexIn(Q_ParticlesType.section(Q_ParticlesSeperator, zaehler, zaehler, QString::SectionSkipEmpty));
int posM2 = Q_GetFloat.indexIn(Q_GetMass.cap(0));
std::cout << Q_GetFloat.cap(2).toStdString() << std::endl;
ParticleSpecs.Mass[zaehler] = Q_GetFloat.cap(2).toFloat();
}
}
NumberParticles=0;
for (unsigned int zaehler=0; zaehler<NumberOfSpecies; zaehler++)
{
NumberParticles+=ParticleSpecs.Number[zaehler];
}
}
Class MDBase
The class SolverBase includes the virtual run function that performs the MD simulation and declares the technical numbers needed for Cuda
class MDBase { public: virtual void run() = 0; unsigned int BlocksPerGrid; unsigned int ThreadsPerBlock; };
Template Class MDSolver
The Template class will realize the choice of the solver and is derived from MDBase
template <solver s, boundary b> class MDSolver : public MDBase { public: MDSolver(const BasicParamsType &BasicParams, const ParticleTypeSpecs &ParticleSpecs); virtual void run(); private: const BasicParamsType *BasicParams; const ParticleTypeSpecs *ParticleSpecs; }; } // namespace step13 END #endif // MDSolver_STEP_13_H #ifndef CUDA_DRIVER_STEP_13_HH #define CUDA_DRIVER_STEP_13_HH #include "cuda_driver_step-13.h" #include "particles_step-13.h" #include "cuda_kernel_wrapper_step-13.cu.h" #include <ctime>
Interface Between the user Input and the Physics of the Simulation
Constructor: MDSolver
The constructer gets informations about the BasicParams which are necessary for the physics of the simulation. Additionally it calculates and defines the grid and block size.
template <solver s, boundary b> step13::MDSolver<s, b>::MDSolver(const BasicParamsType &Params, const ParticleTypeSpecs &ParticleSpecs) : BasicParams(&Params),ParticleSpecs(&ParticleSpecs) { ThreadsPerBlock = 256; BlocksPerGrid = static_cast<unsigned int> (ceil(static_cast<float>(Params.NumberParticles) /static_cast<float>(ThreadsPerBlock))); }
Function: run
This is the definition of the method run for the template call MDSolver See the printf that are commented out; they describe the main loop.
template <solver s, boundary b> void step13::MDSolver<s, b>::run() {
The stepnumber checks if a configuration has to be putted out and a measurement has to be performed
unsigned int stepnumber=0; clock_t timerA=clock(); clock_t timerB; printf("Start \n");
Construct the Particles class.
Particles<s, b> p(*BasicParams, *ParticleSpecs);
The next line will appear more often. It catches errors thrown by cuda.
cuda_check_errors(__FILE__, __LINE__);
printf("TeilchenSystem angelegt \n");
This is the main loop in which the integration is performed
for (float time=0.0; time < BasicParams->Time; time += BasicParams->TimeStep ) { p._calc_id(ThreadsPerBlock, BlocksPerGrid); cuda_check_errors(__FILE__, __LINE__); cudaThreadSynchronize(); / *printf("CellIds berechnet \n");* / p._sort(); cuda_check_errors(__FILE__, __LINE__); / *printf("Daten vorsortiert \n");* / p._reorder(ThreadsPerBlock, BlocksPerGrid); cudaThreadSynchronize(); p._copy_sorted_data(); / *printf("Daten sortiert \n");* / cudaThreadSynchronize(); p._integrate(ThreadsPerBlock, BlocksPerGrid, stepnumber % BasicParams->measure, time); cudaThreadSynchronize(); / *printf("Integriert \n");* / timerB = clock();
The next statement gives an output every BasicParams->measure timestep
if (stepnumber % BasicParams->measure == 0)
{
p.put_out(time);
cuda_check_errors(__FILE__, __LINE__);
std::cout << (double)(timerB-timerA)/(double)(CLOCKS_PER_SEC) << "\t";
}
stepnumber++;
}
std::cout << (double)(timerB-timerA)/(double)(CLOCKS_PER_SEC) << std::endl;
}
#endif // CUDA_DRIVER_STEP_13_HH
#ifndef INTEGRATION_STEP_13_H
#define INTEGRATION_STEP_13_H
Integration
This section implements the main loop, especially the force computation as well as the integration
Definition of constants and declarations
The following constants are important for gears integration scheme
#define c0 0.1875 #define c1 0.697222222222 #define c2 1.0 #define c3 0.611111111111 #define c4 0.166666666667 #define c5 0.0166666666667
Decalaration of the device and global functions
__global__ void calcid(const float2* pos, unsigned int *CellId, unsigned int *PId, BasicParamsType BasicParams); __global__ void reorder(unsigned int *CellStart, unsigned int *CellEnd, float2 *inPos, float2 *outPos, float2 *inVel, float2 *outVel, float2* inForce, float2* outForce, float2* inr3dot, float2* outr3dot, float2* inr4dot , float2* outr4dot, float2* inr5dot, float2* outr5dot, unsigned int* inParticleType, unsigned int* outParticleType, unsigned int *CellId, unsigned int *PId, unsigned int NumberParticles); template<typename Stepper, typename Boundary> __global__ void integrate(float2* Pos, float2* Vel, float2* Force, float2* r3dot, float2* r4dot, float2* r5dot, float2* Force_predict, const unsigned int* CellStart, const unsigned int* CellEnd, BasicParamsType BasicParams, Stepper propagate, float time); __device__ void check_boundary(float2* Pos, float lx, float ly); __global__ void force(const float2* Pos, const float2* Vel, float2* Force, const unsigned int* CellStart, const unsigned int* CellEnd, const float2* R, const unsigned int* ParticleType, BasicParamsType BasicParams); __device__ float2 calc_force(unsigned int index, int2 shift, const float2* Pos, const float2* Vel, const unsigned int* CellStart, const unsigned int* CellEnd, float2* R, unsigned int* ParticleType, BasicParamsType BasicParams); __device__ float2 collide(float2 posa, float2 vela, float2 posb, float2 velb, const float2* R, const unsigned int* ParticleType, const unsigned int index, const unsigned int count, const float lx, const float ly); __device__ float Overlap(const float2 pa, const float2 pb, const float r1, const float r2, const float lx, const float ly, int2* sign); __device__ float2 RelVel(const float2 pa, const float2 pb); __device__ int shifts(int d, float l); __device__ uint2 getCell(float2 pos); __device__ unsigned int calc_single_CellId(int2 shift, float SystemSizeX,float SystemSizeY); #endif //INTEGRATION_STEP_13_H #include "integration_step-13.h" #include "cutil_math.h"
Function: calcid
Calculates the CellIds und PIds. Linewise the cells are numbered and a particle wit x component between i und i+1 y component between j and j+1 gets the CellId CellId = i + j*"maximal i in x-direction"
__global__ void calcid(const float2 *pos, unsigned int *CellId, unsigned int *PId, BasicParamsType BasicParams) { unsigned int index = blockIdx.x*blockDim.x + threadIdx.x; if (index >= BasicParams.NumberParticles) {return;} CellId[index] = static_cast<int>(floor(pos[index].x)) + static_cast<int>(floor(pos[index].y)*ceil(BasicParams.SystemSizeX)); PId[index] = index; }
Function: reorder
Sorts the device data so that the vectors are sorted with respect to the PId. The CellStart and CellEnd is computed too; see S.Green 2008 (NVIDIA)
__global__ void reorder(unsigned int *CellStart, unsigned int *CellEnd, float2 *inPos, float2 *outPos, float2 *inVel, float2 *outVel, float2* inForce, float2* outForce, float2* inr3dot, float2* outr3dot, float2* inr4dot , float2* outr4dot, float2* inr5dot, float2* outr5dot, unsigned int* inParticleType, unsigned int* outParticleType, unsigned int *CellId, unsigned int *PId, unsigned int NumberParticles) {
Shared memory can be seen in the thread block. The qualifier 'extern' provides that the size of the array is determined at launch time. The size has to be put in the kernel call as a third argument
extern __shared__ unsigned int sharedCellId[]; unsigned int index = blockIdx.x*blockDim.x + threadIdx.x; unsigned int cellid; if (index < NumberParticles) {
Initialize the shared array with the cellids
cellid = CellId[index];
Shared memory in different blocks are independent!
sharedCellId[threadIdx.x+1] = cellid;
For communication between blocks the first entry is responsible index > 0 && threadIdx.x == 0 corresponds to the first thread in a block which is not the zeroth
if (index > 0 && threadIdx.x == 0)
{
each (per block) sharedCellId[0] gets the CellId of the last thread in the block with a blockindex decremented by one
sharedCellId[0] = CellId[index-1];
}
}
now the shared array is complete
__syncthreads();
if (index < NumberParticles)
{
The first index corresponds to a start if the cellid is unequal to the cellId of the last thread. One has to take the shift in the shared array into account.
if (index == 0 || cellid != sharedCellId[threadIdx.x])
{
CellStart[cellid] = index;
if the index is greater than 0 a cell end is given by the cellid of the last thread
if (index > 0)
CellEnd[sharedCellId[threadIdx.x]] = index;
}
the last index corresponds to an end
if (index == NumberParticles -1)
{
CellEnd[cellid] = index + 1;
}
Now the device data will be sorted
unsigned int sortedPId = PId[index]; outPos[index] = inPos[sortedPId]; outVel[index] = inVel[sortedPId]; outForce[index] = inForce[sortedPId]; outr3dot[index] = inr3dot[sortedPId]; outr4dot[index] = inr4dot[sortedPId]; outr5dot[index] = inr5dot[sortedPId]; outParticleType[index] = inParticleType[sortedPId]; } }
Function: getCell
Calculates the integer coordinate of the particle
__device__ uint2 getCell(float2 pos)
{
return make_uint2(floor(pos.x),floor(pos.y));
}
Function: calc_single_CellId
Calculates the integer cell coordinaten and takes boundary into account
__device__ unsigned int calc_single_CellId(int2 shift, float SystemSizeX,float SystemSizeY) { return static_cast<unsigned int>(shift.x) %static_cast<unsigned int>(ceil(SystemSizeX)) + (static_cast<unsigned int>(shift.y) %static_cast<unsigned int>(ceil(SystemSizeY)))*static_cast<unsigned int>(ceil(SystemSizeX)); }
Function: Overlap
Computes the overlap
__device__ float Overlap(const float2 pa, const float2 pb, const float r1, const float r2, const float lx, const float ly, int2* sign) { float dx = pa.x - pb.x;
weiter als lx-2*teilchendurchmesser (oder -radius?) bzw 2*boxabmessung können teilchen nicht entfernt sein fixme: achtung nur für monodispers und systeme, die groß genug sind
if (dx > lx-(1.0+1.0)) {dx -=lx; sign->x*=-1;} else if (dx < -lx+(1.0+1.0)) {dx +=lx; sign->x*=-1;} float dy = pa.y - pb.y; if (dy > ly-(1.0+1.0)) {dy -=ly; sign->y*=-1;} else if (dy < -ly+(1.0+1.0)) {dy +=ly; sign->y*=-1;}
sum of the radii (0.5 each) minus distance
float local_overlap = r1 + r2 - sqrt(dx*dx+dy*dy); return local_overlap; }
Function: RelVel
Computes the relative velocity
__device__ float2 RelVel(const float2 pa, const float2 pb) { float dvx = pa.x-pb.x; float dvy = pa.y-pb.y; return make_float2(dvx, dvy); }
Function: shifts
Shifts the grid position if pbc are applied
__device__ int shifts(int d, float l) { if (d < 0) {d += static_cast<int>(ceil(l));} else if (d >= l) {d -= static_cast<int>(ceil(l));} return d; }
Function: collide
Calculates the force between a pair of particles
__device__ float2 collide(float2 posa, float2 vela, float2 posb, float2 velb, const float2* R, const unsigned int* ParticleType, const unsigned int index, const unsigned int count, const float lx, const float ly) { int2 sign=make_int2(1,1); float2 force_local=make_float2(0,0); float local_overlap=Overlap(posa, posb, R[ParticleType[index]].x, R[ParticleType[count]].x, lx, ly, &sign);
normalize(float2 v) returns a unit vector in direction of v
If and only if the particles overlap an interaction is given
if (local_overlap > 0.0)
{
force_local += RelVel(velb, vela);
force_local -= local_overlap*make_float2(sign)*normalize(posb-posa);
}
fixme: hier effektive masse richtig?
return force_local*(R[ParticleType[index]].y*R[ParticleType[count]].y)/(R[ParticleType[index]].y+R[ParticleType[count]].y);
}
Function: calc_force
Calculates the force between the a given particle and particles in neighboring cells
__device__ float2 calc_force(unsigned int index, int2 shift, const float2* Pos, const float2* Vel, const unsigned int* CellStart, const unsigned int* CellEnd, const float2* R, const unsigned int* ParticleType, BasicParamsType BasicParams) { float2 force_local= make_float2(0,0); unsigned int cellid = calc_single_CellId(shift, BasicParams.SystemSizeX, BasicParams.SystemSizeY);
Not all entries correspond to starts!
unsigned int startIndex = CellStart[cellid];
printf("%d %d \t",startIndex, cellid);
if (startIndex != 0xffffffff) { unsigned int endIndex = CellEnd[cellid];
printf("l(%d %d %d) \t",startIndex, endIndex, cellid);
for (unsigned int count=startIndex; count < endIndex; count++) {
Excludes collisions with itself
if(count != index) { force_local += collide(Pos[index], Vel[index], Pos[count], Vel[count], R, ParticleType, index, count, BasicParams.SystemSizeX, BasicParams.SystemSizeY); } } } return force_local; }
Function: force
Calculates the force between all particles
__global__ void force(const float2* Pos, const float2* Vel, float2* Force, const unsigned int* CellStart, const unsigned int* CellEnd, const float2* R, const unsigned int* ParticleType, BasicParamsType BasicParams) { unsigned int index = blockIdx.x*blockDim.x + threadIdx.x; if (index >= BasicParams.NumberParticles) { return; } float2 pos = Pos[index]; uint2 gridpos = getCell(pos); float2 force_local = make_float2(0,0);
Loop from -1 to 1 to follows newtons law It means that every interaction is calculated twice (to think about)
for (int y=-1; y <=1; y++ ) { for (int x=-1; x <=1; x++ ) {
Deklares and defines the location of the neighboring cells. Shift corresponds to the particluar cells surrounding the cell that the particle index contains.
int2 shift = make_int2(x,y) + make_int2(gridpos.x,gridpos.y);
'shifts()' is necessary for pbc
shift.x = shifts(shift.x, BasicParams.SystemSizeX);
shift.y = shifts(shift.y, BasicParams.SystemSizeY);
force_local += calc_force(index, shift, Pos, Vel, CellStart, CellEnd, R, ParticleType, BasicParams);
}
}
Force[index] = force_local;
}
Function: boundary
Shifts particles in the correct image
__device__ void check_boundary(float2* Pos, float lx, float ly) { if (Pos->x < 0.0) {Pos->x+=lx;} else if (Pos->x > lx) {Pos->x-=lx;} if (Pos->y < 0.0) {Pos->y+=ly;} else if (Pos->y > ly) {Pos->y-=ly;} }
This will be the next implementation of pbc
class Pbc { public: __device__ Pbc() {} __device__ __forceinline__ void operator() (float2* Pos, float2* Vel, float lx, float ly, float time) const { if (Pos->x < 0.0) {Pos->x+=lx;} else if (Pos->x > lx) {Pos->x-=lx;} if (Pos->y < 0.0) {Pos->y+=ly;} else if (Pos->y > ly) {Pos->y-=ly;} } };
Implementation of the Lees-Edwards boundary conditions
class LeesEdwards { public:
time entspricht der in der simulation vergangenen zeit
__device__ LeesEdwards()
:
__g(4.0)
{}
__device__ __forceinline__ void operator() (float2* Pos,
float2* Vel,
float lx,
float ly,
float time) const
{
if (Pos->y < 0.0) {Pos->y+=ly; Pos->x+=time*__g; Vel->x+=__g;}
else if (Pos->y > ly) {Pos->y-=ly; Pos->x-=time*__g; Vel->x-=__g;}
while (Pos->x < 0.0) {Pos->x+=lx;} while (Pos->x > lx) {Pos->x-=lx;}
if (Pos->x < 0.0) {Pos->x = fmod(Pos->x, lx); Pos->x +=lx;} if (Pos->x > lx) {Pos->x= fmod(Pos->x, lx);} } private: float __g; };
Time Integration Schemes
Class: Euler
Notice: it is neither necessary nor meaningful to give the euler integration the informations about higher order derivates than 2. This has to be corrected.
template <typename Boundary> class Euler { public: __device__ Euler(float dt) : __dt(dt) {} __device__ __forceinline__ void operator() (unsigned int index, float2& pos_local, float2& vel_local, const float2* Pos, float2* Vel, float2* Force, float2* r3dot, float2* r4dot, float2* r5dot, float2* Force_predict, const unsigned int* CellStart, const unsigned int* CellEnd, Boundary apply_boundary, const BasicParamsType BasicParams, float time) const { pos_local = pos_local + vel_local * __dt; apply_boundary(&pos_local, &vel_local, BasicParams.SystemSizeX, BasicParams.SystemSizeY, time); vel_local = vel_local + Force[index] * __dt; } private: float __dt; };
Class: Gear
Here the correction is done. It would be wise to compute the coefficients ai, bj once and hand them over instead to compute them at every time step!
template <typename Boundary> class Gear { public: __device__ Gear(float dt) : __dt(dt) { } __device__ __forceinline__ void operator() (unsigned int index, float2& pos_local, float2& vel_local, float2* Pos, float2* Vel, float2* Force, float2* r3dot, float2* r4dot, float2* r5dot, float2* Force_predict, const unsigned int* CellStart, const unsigned int* CellEnd, Boundary apply_boundary, const BasicParamsType BasicParams, float time) const { float a1 = __dt; float a2 = a1*__dt/2.0; float a3 = a2*__dt/3.0;
Correct
float b0 = c0 * a2; float b1 = c1 * a1 / 2.0; float b2 = c2; float b3 = c3 / (3.0*__dt); float b4 = c4 * 6.0 / (a2); float b5 = c5 * 2.5 / (a3); float2 corr = Force[index] - Force_predict[index]; pos_local += b0 * corr; apply_boundary(&pos_local, &vel_local, BasicParams.SystemSizeX, BasicParams.SystemSizeY, time); vel_local += b1 * corr; Force[index] = Force_predict[index] + b2*corr; r3dot[index] += b3 * corr; r4dot[index] += b4 * corr; r5dot[index] += b5 * corr; } private: float __dt; };
Function: predict
Here the prediction for the gear scheme is performed. It would be wise to compute the coefficients once and hand them over instead to compute them at every time step!
template<typename Stepper, typename Boundary> __global__ void predict(float2* Pos, float2* Vel, float2* Force, float2* r3dot, float2* r4dot, float2* r5dot, float2* Force_predict, BasicParamsType BasicParams, float time) { unsigned int index = blockIdx.x*blockDim.x + threadIdx.x; if (index >= BasicParams.NumberParticles) {return;} Boundary apply_boundary; float dt = BasicParams.TimeStep; float a1 = dt; float a2 = a1*dt/2.0; float a3 = a2*dt/3.0; float a4 = a3*dt/4.0; float a5 = a4*dt/5.0;
Predict
Pos[index] += a1*Vel[index] + a2*Force[index] + a3*r3dot[index] + a4*r4dot[index] + a5*r5dot[index];
apply_boundary(&Pos[index], &Vel[index],BasicParams.SystemSizeX, BasicParams.SystemSizeY, time);
Vel[index] += a1*Force[index] + a2*r3dot[index] + a3*r4dot[index] + a4*r5dot[index];
Force_predict[index] = Force[index] + a1*r3dot[index] + a2*r4dot[index] + a3*r5dot[index];
r3dot[index] += a1*r4dot[index] + a2*r5dot[index];
r4dot[index] += a1*r5dot[index];
}
Function: integrate
This is the integration routine. If the forces and the necessary data are given Stepper chooses the according integration routine.
template<typename Stepper, typename Boundary> __global__ void integrate(float2* Pos, float2* Vel, float2* Force, float2* r3dot, float2* r4dot, float2* r5dot, float2* Force_predict, const unsigned int* CellStart, const unsigned int* CellEnd, BasicParamsType BasicParams, float time) { Stepper propagate(BasicParams.TimeStep); Boundary apply_boundary; unsigned int index = blockIdx.x*blockDim.x + threadIdx.x; if (index >= BasicParams.NumberParticles) {return;} float2 pos_local = Pos[index]; float2 vel_local = Vel[index];
Do time step
propagate(index,
pos_local, vel_local,
Pos, Vel, Force,
r3dot, r4dot, r5dot, Force_predict,
CellStart, CellEnd,
apply_boundary,
BasicParams,
time);
Pos[index] = pos_local;
Vel[index] = vel_local;
}
#ifndef PARTICLES_STEP_13_H
#define PARTICLES_STEP_13_H
#include <iostream>
#include <cstdlib>
#include <fstream>
#include <vector>
#include <QString>
#include <QRegExp>
#include <cstring>
This library contains vector handling on the device
#include <thrust/device_vector.h> #include <thrust/host_vector.h> #include "cuda_kernel_wrapper_step-13.cu.h" using namespace std;
Used data structures, Particles class and additional definitions
overloads the operator << in order to put float2 out
ostream & operator <<(ostream &os, const float2 data); // DER KAN NWEG; DAS DEN OPERATOR SCHON IN cublas_vector.h GIBT!!!
overloads the operator >> in order to read float2 in
ifstream & operator >>(ifstream &is, float2* data);
Class Particles
This class contains the information about all the particles. The template parameter is the solver scheme
template<solver s, boundary b> class Particles { public:
working with thrust host and device vectors
typedef thrust::host_vector<float2> ParticleDataContainerHost; typedef thrust::device_vector<float2> ParticleDataContainerDev; typedef thrust::host_vector<unsigned int> IndexArrayHost; typedef thrust::device_vector<unsigned int> IndexArray;
Constructor
Particles(const BasicParamsType &Params, const ParticleTypeSpecs &ParticleSpecs) :BasicParams(&Params),ParticleSpecs(&ParticleSpecs) { init_particles(); }
Destructor
~Particles()
{
finalize_particles();
}
Initialization of the particles
void init_particles();
Destruct the particles
void finalize_particles();
Method to print particle configuration
void put_out(float time);
Method to read in a particle configuration
void read_in();
Method to start the kernel wrapper function for computing the CellIds
void _calc_id(unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid) { h_calcid(thrust::raw_pointer_cast(&Pos[0]), thrust::raw_pointer_cast(&CellId[0]), thrust::raw_pointer_cast(&PId[0]), *BasicParams, ThreadsPerBlock, BlocksPerGrid); }
Method to sort the Ids
void _sort() { IndexArrayHost host_cell; IndexArrayHost host_pid; host_cell.resize(BasicParams->NumberParticles); host_pid.resize(BasicParams->NumberParticles); cudaMemcpy((void *)thrust::raw_pointer_cast(&host_cell[0]),(void *)thrust::raw_pointer_cast(&CellId[0]), BasicParams->NumberParticles*sizeof(unsigned int), cudaMemcpyDeviceToHost); cudaMemcpy((void *)thrust::raw_pointer_cast(&host_pid[0]),(void *)thrust::raw_pointer_cast(&PId[0]), BasicParams->NumberParticles*sizeof(unsigned int), cudaMemcpyDeviceToHost); sort(thrust::raw_pointer_cast(&host_cell[0]),thrust::raw_pointer_cast(&host_pid[0]), BasicParams->NumberParticles); cudaMemcpy((void *)thrust::raw_pointer_cast(&CellId[0]),(void *)thrust::raw_pointer_cast(&host_cell[0]), BasicParams->NumberParticles*sizeof(unsigned int), cudaMemcpyHostToDevice); cudaMemcpy((void *)thrust::raw_pointer_cast(&PId[0]), (void *)thrust::raw_pointer_cast(&host_pid[0]), BasicParams->NumberParticles*sizeof(unsigned int), cudaMemcpyHostToDevice); }
Method to compute the forces
void _force(unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid) { h_force(thrust::raw_pointer_cast(&Pos[0]), thrust::raw_pointer_cast(&Vel[0]), thrust::raw_pointer_cast(&Force[0]), thrust::raw_pointer_cast(&CellStart[0]), thrust::raw_pointer_cast(&CellEnd[0]), thrust::raw_pointer_cast(&R[0]), thrust::raw_pointer_cast(&ParticleType[0]), *BasicParams, ThreadsPerBlock, BlocksPerGrid); }
Method to start the kernel wrapper function for reordering the data
void _reorder(unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid) { h_reorder(thrust::raw_pointer_cast(&CellStart[0]), thrust::raw_pointer_cast(&CellEnd[0]), thrust::raw_pointer_cast(&Pos[0]), thrust::raw_pointer_cast(&Pos_sorted[0]), thrust::raw_pointer_cast(&Vel[0]), thrust::raw_pointer_cast(&Vel_sorted[0]), thrust::raw_pointer_cast(&Force[0]), thrust::raw_pointer_cast(&Force_sorted[0]), thrust::raw_pointer_cast(&r3dot[0]), thrust::raw_pointer_cast(&r3dot_sorted[0]), thrust::raw_pointer_cast(&r4dot[0]), thrust::raw_pointer_cast(&r4dot_sorted[0]), thrust::raw_pointer_cast(&r5dot[0]), thrust::raw_pointer_cast(&r5dot_sorted[0]), thrust::raw_pointer_cast(&ParticleType[0]), thrust::raw_pointer_cast(&ParticleType_sorted[0]), thrust::raw_pointer_cast(&CellId[0]), thrust::raw_pointer_cast(&PId[0]), *BasicParams, ThreadsPerBlock, BlocksPerGrid); }
Method to copy sorted data to unsorted data
void _copy_sorted_data()
{
Pos=Pos_sorted; Vel=Vel_sorted; Force=Force_sorted;
r3dot=r3dot_sorted; r4dot=r4dot_sorted; r5dot=r5dot_sorted;
ParticleType = ParticleType_sorted;
}
Method to start the kernel wrapper function for performing the time step
void _integrate(unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid, int flag, float time); void _predict(unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid); private: const BasicParamsType *BasicParams; const ParticleTypeSpecs *ParticleSpecs; __device__ __constant__ BasicParamsType dev_BasicParams;
Device vectors containing the masses and radii of the particles. R contains the radii in entry x as well as the mass in entry y
ParticleDataContainerDev R;
IndexArray ParticleType will store the 'number' of the species. i.e the first type is named 0, the second type is name 1...
IndexArray ParticleType; IndexArray ParticleType_sorted;
Device data
ParticleDataContainerDev Pos, Vel, Force, Pos_sorted, Vel_sorted, Force_sorted;
Device container which are for solving higher order schemes: Each d corresponds to a derivate with respect to t.
ParticleDataContainerDev r3dot, r4dot, r5dot, Force_predict; ParticleDataContainerDev r3dot_sorted, r4dot_sorted, r5dot_sorted;
CellId stores the CellIds of the particles numbered by the index given by PIds. CellStart marks the starts and CellEnd the ends of the new cell in the sorted array; CellEnd[i] - CellStart[i] gives the number of particles in cell [i]
IndexArray PId, CellId, CellStart, CellEnd;
Host data
ParticleDataContainerHost host_Pos, host_Vel, host_Force, RHost; };
Definition of the integration function
template <solver s, boundary b> void Particles<s, b>::_integrate(unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid, int flag, float time) { StepperScheme<s, b>::h_integrate(thrust::raw_pointer_cast(&Pos[0]), thrust::raw_pointer_cast(&Vel[0]), thrust::raw_pointer_cast(&Force[0]), thrust::raw_pointer_cast(&r3dot[0]), thrust::raw_pointer_cast(&r4dot[0]), thrust::raw_pointer_cast(&r5dot[0]), thrust::raw_pointer_cast(&Force_predict[0]), thrust::raw_pointer_cast(&CellStart[0]), thrust::raw_pointer_cast(&CellEnd[0]), thrust::raw_pointer_cast(&R[0]), thrust::raw_pointer_cast(&ParticleType[0]), *BasicParams, thrust::raw_pointer_cast(&host_Pos[0]), thrust::raw_pointer_cast(&host_Vel[0]), thrust::raw_pointer_cast(&host_Force[0]), flag, ThreadsPerBlock, BlocksPerGrid, time); }
// Definition of the prediction function template <solver s, boundary b> void Particles<s, b>::_predict(unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid) { StepperScheme<s, b>::h_predict(thrust::raw_pointer_cast(&Pos[0]), thrust::raw_pointer_cast(&Vel[0]), thrust::raw_pointer_cast(&Force[0]), thrust::raw_pointer_cast(&r3dot[0]), thrust::raw_pointer_cast(&r4dot[0]), thrust::raw_pointer_cast(&r5dot[0]), thrust::raw_pointer_cast(&Force_predict[0]), *BasicParams, ThreadsPerBlock, BlocksPerGrid, time); }
#include "particles_step-13.hh" #endif //PARTICLES_STEP_13_H #ifndef PARTICLES_STEP_13_HH #define PARTICLES_STEP_13_HH #include "particles_step-13.h" #include "cutil_inline.h" #include "thrust/sort.h"
Function: init_particles
The method init_particles() reserves memory and sets the start position and velocity values. This method is called in the constructor for a Particles object
template <solver s, boundary b> void Particles<s, b>::init_particles() {
The std vectors get the proper size
host_Pos.resize(BasicParams->NumberParticles);
host_Vel.resize(BasicParams->NumberParticles);
host_Force.resize(BasicParams->NumberParticles);
Vector which will initialize the other vectors with '0'
ParticleDataContainerHost initializer;
initializer.resize(BasicParams->NumberParticles);
ParticleType.Reinit(BasicParams->NumberParticles);
use polydisperisty
IndexArrayHost ParticleTypeHost;
ParticleTypeHost.resize(BasicParams->NumberParticles);
ParticleType = ParticleTypeHost;
ParticleType_sorted = ParticleTypeHost;
unsigned int type=0;
unsigned int temp_number=0;
versieht die teilchen mit ihren ParticleTypes
for (unsigned int zaehler=0; zaehler<BasicParams->NumberParticles; zaehler++) { ParticleTypeHost[zaehler] = type; if ( ParticleSpecs->Number[type] == zaehler-1) type++; } ParticleType = ParticleTypeHost; / * R.resize(ParticleSpecs->NSpecies); * / RHost.resize(ParticleSpecs->NSpecies); R = RHost; for (type=0; type<ParticleSpecs->NSpecies; type++) { RHost[type].x = ParticleSpecs->Radius[type]; RHost[type].y = ParticleSpecs->Mass[type]; } R = RHost;
Creates a random particle configuration
if (BasicParams->PConf == rnd)
{
Uses a defined seed value which makes a reproduction of data possible
srand(BasicParams->Seed);
for (unsigned int count=0; count < BasicParams->NumberParticles; count++)
{
equally distributed locations in the simulation area
host_Pos[count].x = BasicParams->SystemSizeX*
static_cast<float>(rand())/static_cast<float>(RAND_MAX);
host_Pos[count].y = BasicParams->SystemSizeY*
static_cast<float>(rand())/static_cast<float>(RAND_MAX);
warning: nonphysical (equal) distribution of the velocities in [-1:1]
host_Vel[count].x = -1.0
+2.0*static_cast<float>(rand())/static_cast<float>(RAND_MAX);
/ *host_Vel[count].y = -1.0
+2.0*static_cast<float>(rand())/static_cast<float>(RAND_MAX);* /
host_Vel[count].y = 0.0;
initializer[count].x = 0.0;
initializer[count].y = 0.0;
host_Force[count].x = 0.0;
host_Force[count].y = 0.0;
}
}
Reads a given configuration from the file 'conf.test'
FIXME: to be checked...particle type
if (BasicParams->PConf == conf) { float2 R_temp; ifstream infile ("conf.test"); for (unsigned int count=0; count < BasicParams->NumberParticles; count++) { if (infile.good()) { infile >> &host_Pos[count] >> &host_Vel[count] >> &host_Force[count] >> &R_temp; for (type=0; type<ParticleSpecs->NSpecies; type++) { if (RHost[type].x == R_temp.x && RHost[type].y == R_temp.y) ParticleTypeHost[count] = type; } } else { std::cerr << "Error while reading configuration" << std::endl; exit(-1); } initializer[count].x = 0.0; initializer[count].y = 0.0; } ParticleType = ParticleTypeHost; infile.close(); }
Copy host data to device (operator '=' is overloaded for std-vector=cublas-vector)
Pos = host_Pos;
Vel = host_Vel;
Force = host_Force;
/ *Pos_sorted.resize(Pos.size());
Vel_sorted.resize(Vel.size());
Force_sorted.resize(Force.size());* /
Pos_sorted = initializer;
Vel_sorted = initializer;
Force_sorted = initializer;
Initialze higher order derivatives
/ *r3dot.resize(Pos.size());
r4dot.resize(Pos.size());
r5dot.resize(Pos.size());
Force_predict.resize(Pos.size());* /
r3dot = initializer;
r4dot = initializer;
r5dot = initializer;
Force_predict = initializer;
r3dot = initializer;
r4dot = initializer;
r5dot = initializer;
Force_predict = initializer;
/ *
r3dot_sorted.resize(Pos.size());
r4dot_sorted.resize(Pos.size());
r5dot_sorted.resize(Pos.size());
* /
r3dot_sorted = initializer;
r4dot_sorted = initializer;
r5dot_sorted = initializer;
Compute the number of cells
unsigned int NumCellsX = calc_NumberOfCellsX(BasicParams->SystemSizeX); unsigned int NumCellsY = calc_NumberOfCellsY(BasicParams->SystemSizeY); unsigned int NumberOfCells=calc_NumberOfCells(NumCellsX, NumCellsY);
Use the computed number to initialize the vectors for organization
IndexArrayHost init_int;
init_int.resize(NumberOfCells);
CellStart = init_int;
CellEnd = init_int;
/ *
CellStart.resize(NumberOfCells);
CellEnd.resize(NumberOfCells);
* /
init_int.resize(BasicParams->NumberParticles);
PId = init_int;
CellId = init_int;
/ *
PId.resize(BasicParams->NumberParticles);
CellId.resize(BasicParams->NumberParticles);
* /
Kopiert die Parameter in den constant-Memory, da sie ab hier nicht mehr ueberschrieben werden CUDA_SAFE_CALL(cudaMemcpyToSymbol("dev_BasicParams", (void *)BasicParams, sizeof(*BasicParams),0,cudaMemcpyHostToDevice));
}
Function: finalize_particles
Not much has to be destroyed by hand. This method is called in the destructor for a Particles object
template <solver s, boundary b> void Particles<s, b>::finalize_particles() {
This function is empty... the function was written in order to destroy the cudpp-sortplan and is obsolete now
}
{Function: sort}
This function calls the thrust library.
void sort(unsigned int* CellId, unsigned int* PId, unsigned int NumElements) { thrust::sort_by_key(CellId, CellId + NumElements, PId); }
{Function: operator <<}
Put out float2.
KANN WEG. GIBT ES SCHON IN cublas_vector.h
ostream & operator <<(ostream &os, const float2 data) { os << data.x << "\t" << data.y; return os; }
{Function: operator >>}
Read in float2.
ifstream & operator >>(ifstream &is, float2* data)
{
is >> data->x >> data->y;
return is;
}
{Function: put_out}
Creates the output on stdout and will create configurations (not yet implemented properly).
template <solver s, boundary b> void Particles<s, b>::put_out(float time) { float px=0.0; float py=0.0; float ekin=0.0; ParticleDataContainerHost RHost=R; IndexArrayHost ParticleTypeHost=ParticleType; if ( QString::compare(QString(BasicParams->fileout),QString("none"))) { QString filename((BasicParams->fileout)); QString Q_Time; Q_Time.setNum(time,'f',6); filename.append("_"); filename.append(Q_Time); filename.append(".dat"); std::ofstream fileout; fileout.open(filename.toStdString().c_str()); fileout.setf(ios::fixed, ios::floatfield); for (size_t i=0; i < BasicParams->NumberParticles; i++) { px += host_Vel[i].x; py += host_Vel[i].y; ekin += host_Vel[i].x*host_Vel[i].x + host_Vel[i].y*host_Vel[i].y; { fileout << host_Pos[i] << "\t" << host_Vel[i] << "\t" << host_Force[i] << "\t" << RHost[ParticleTypeHost[i]] << endl;
cout << i << "\t " << host_Pos[i] << "\t" << host_Vel[i] << "\t" << host_Force[i] << "\t" << RHost[ParticleTypeHost[i]] << endl;
}
}
fileout.close();
}
else
{
for (size_t i=0; i < BasicParams->NumberParticles; i++)
{
px += host_Vel[i].x;
py += host_Vel[i].y;
ekin += host_Vel[i].x*host_Vel[i].x + host_Vel[i].y*host_Vel[i].y;
}
}
cout << time << "\t" << px << "\t" << py << "\t" << ekin << endl;
}
{Function: calc_NumberOfCellsX}
unsigned int calc_NumberOfCellsX(float SystemSizeX) { return static_cast<unsigned int>(ceil(SystemSizeX)); }
{Function: calc_NumberOfCellsY}
unsigned int calc_NumberOfCellsY(float SystemSizeY) { return static_cast<unsigned int>(ceil(SystemSizeY)); }
{Function: calc_NumberOfCells}
unsigned int calc_NumberOfCells(unsigned int NumberOfCellsX,unsigned int NumberOfCellsY) { return NumberOfCellsX*NumberOfCellsY; } #endif //PARTICLES_STEP_13_HH
STL header
#include <iostream> #include <vector> #include "cuda_driver_step-13.h" #include "cuda_driver_step-13.hh" #define USE_DEAL_II #undef USE_DEAL_II namespace step13 {
Class: MyFancySimulation
This class handles the basics of the simulation
class MyFancySimulation { public: MyFancySimulation(::ParameterHandler &prm_handler); ~MyFancySimulation(); void run(); private: SimulationParams params; MDBase * mdbase; }; }
Constructor: MyFancySimulation
The constructor needs the parameter handler and reads in the parameters. The proper solver is chosen. step13::MyFancySimulation::MyFancySimulation(::ParameterHandler &prm_handler) { params.get(prm_handler);
switch (params.SolverType) { case euler: switch (params.boundary_conditions) { case periodic: mdbase = new step13::MDSolver<euler, periodic>(params,params.ParticleSpecs); printf("EP"); break; case lees_edwards: mdbase = new step13::MDSolver<euler, lees_edwards>(params,params.ParticleSpecs); printf("EL"); break; default: break; } case gear: switch (params.boundary_conditions) { case periodic: mdbase = new step13::MDSolver<gear, periodic>(params,params.ParticleSpecs); printf("GP"); break; case lees_edwards: mdbase = new step13::MDSolver<gear, lees_edwards>(params,params.ParticleSpecs); printf("GL"); break; default: break; } default: break; } }
step13::MyFancySimulation::MyFancySimulation(::ParameterHandler &prm_handler)
{
params.get(prm_handler);
switch (params.SolverType) {
case euler:
if (params.boundary_conditions == periodic)
{
mdbase = new step13::MDSolver<euler, periodic>(params,params.ParticleSpecs);
break;
}
else if (params.boundary_conditions == lees_edwards)
{
mdbase = new step13::MDSolver<euler, lees_edwards>(params,params.ParticleSpecs);
break;
}
else
break;
case gear:
if (params.boundary_conditions == periodic)
{
mdbase = new step13::MDSolver<gear, periodic>(params,params.ParticleSpecs);
break;
}
else if (params.boundary_conditions == lees_edwards)
{
mdbase = new step13::MDSolver<gear, lees_edwards>(params,params.ParticleSpecs);
break;
}
else
break;
default:
break;
}
}
step13::MyFancySimulation::~MyFancySimulation()
{
delete mdbase;
}
Function: run
The simulation is called here!
void step13::MyFancySimulation::run() { mdbase->run(); std::cout << "Fertig." << std::endl; }
Function: main
int main(int / *argc* /, char * / *argv* /[]) { using namespace step13; ::ParameterHandler prm_handler; SimulationParams::declare(prm_handler); std::string prm_filename; prm_filename +="test.prm"; prm_handler.read_input(prm_filename); MyFancySimulation machma(prm_handler); machma.run(); }
Results
Until now (REV 1438, 14.04.2011) some results look quite plausible. Obviously Haffs Law as well as the momentum conservation is working if the timestep of the solver is choosen properly. These are first proofs of the correctness of the code. The usage of the cudpp-Library causes a lot of problems. Especially stability is not given. In that sense it is not possible to simulate systems with a large number of particles and other simulations will crash in arbitrary situations. These instabilities are the reasons why there is no analysis of runtime until now. For further revisions a new library (thrust) will be used and other boundary conditions (Lees-Edwards) will be implemented. All in all the molecular dynamics project seems to be a great basis for further progress and physical investigations. The color of a sphere in the following pictures corresponds to the force that the particluar particle experience.
Haffs Law Typical Screenshot (homogeneous cooling state) Typical Screenshot (cluster fomration) Typical Screenshot (strong cluster formation)



The plain program
(If you are looking at a locally installed CUDA HPC Praktikum version, then the program can be found at .. /.. /testsite / /step-13 /step-cu.cc . Otherwise, this is only the path on some remote server.) #ifndef CUDA_KERNEL_STEP_13_CU_H
#define CUDA_KERNEL_STEP_13_CU_H
#include <iostream>
#include <cutil_inline.h>
enum particleconfig {rnd, conf};
enum boundary {periodic, lees_edwards};
enum solver {euler, gear};
struct ParticleTypeSpecs{
ParticleTypeSpecs(int NumberOfSpecies);
void Reinit(int NumberOfSpecies);
ParticleTypeSpecs() {}
~ParticleTypeSpecs();
int NSpecies;
unsigned int *Number;
float *Mass;
float *Radius;
};
struct BasicParamsType {
BasicParamsType() {}
particleconfig PConf;
boundary boundary_conditions;
solver SolverType;
float SystemSizeX;
float SystemSizeY;
unsigned int NumberParticles;
float Time;
float TimeStep;
unsigned int Seed;
unsigned int measure;
const char* fileout;
};
inline void cuda_check_errors(const char* filename, int line);
void h_calcid(const float2 *pos, unsigned int *CellId, unsigned int *PId,
const BasicParamsType dev_BasicParams,
unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid);
void sort(unsigned int *CellId, unsigned int *PId,
unsigned int NumberParticles);
void h_reorder(unsigned int *CellStart, unsigned int *CellEnd,
float2 *inPos, float2 *outPos, float2 *inVel, float2 *outVel,
float2* inForce, float2* outForce, float2* inr3dot, float2* outr3dot,
float2* inr4dot , float2* outr4dot, float2* inr5dot, float2* outr5dot,
unsigned int* inParticleType, unsigned int* outParticleType,
unsigned int *CellId, unsigned int *PId,
const BasicParamsType &BasicParams,
unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid);
void h_force(const float2* Pos, const float2* Vel, float2* Force,
const unsigned int* CellStart, const unsigned int* CellEnd,
const float2* R,
const unsigned int* ParticleType,
BasicParamsType BasicParams,
unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid);
inline void cuda_check_errors(const char* filename, int line)
{
#ifdef DEBUG
cudaThreadSynchronize();
cudaError_t error = cudaGetLastError();
if(error != cudaSuccess)
{
printf("CUDA error at %s:%d: %s", filename, line, cudaGetErrorString(error));
exit(-1);
}
#endif
}
unsigned int calc_NumberOfCellsX(float SystemSizeX);
unsigned int calc_NumberOfCellsY(float SystemSizeY);
unsigned int calc_NumberOfCells(unsigned int NumberOfCellsX,unsigned int NumberOfCellsY);
template <solver s, boundary b> struct StepperScheme
{
static const solver SolverType=s;
static const boundary BoundaryType=b;
static void h_integrate(float2* Pos, float2* Vel, float2* Force,
float2* r3dot, float2* r4dot, float2* r5dot,
float2* Force_predict,
const unsigned int *CellStart, const unsigned int *CellEnd,
const float2* R,
const unsigned int* ParticleType,
const BasicParamsType &BasicParams,
float2* host_Pos, float2* host_Vel, float2* host_Force, int flag,
unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid,
float time);
};
#endif // CUDA_KERNEL_STEP_13_CU_H
#include <cutil_inline.h>
#include <cuda_kernel_wrapper_step-13.cu.h>
#include "integration_step-13.h"
#include "integration_step-13.cu.c"
void h_calcid(const float2 *pos, unsigned int *CellId, unsigned int *PId,
const BasicParamsType BasicParams,
unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid)
{
dim3 grid(BlocksPerGrid);
dim3 blocks(ThreadsPerBlock);
calcid<<<grid, blocks>>>(pos, CellId, PId, BasicParams);
cuda_check_errors(__FILE__, __LINE__);
}
void h_reorder(unsigned int *CellStart, unsigned int *CellEnd,
float2 *inPos, float2 *outPos, float2 *inVel, float2 *outVel, float2* inForce, float2* outForce,
float2* inr3dot, float2* outr3dot, float2* inr4dot , float2* outr4dot, float2* inr5dot, float2* outr5dot,
unsigned int* inParticleType, unsigned int* outParticleType,
unsigned int *CellId, unsigned int *PId, const BasicParamsType &BasicParams,
unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid)
{
dim3 grid(BlocksPerGrid);
dim3 blocks(ThreadsPerBlock);
size_t Ns = sizeof(unsigned int)*(blocks.x+1);
cutilSafeCall(cudaMemset((void *)CellStart, 0xffffffff, sizeof(unsigned int)*
calc_NumberOfCells(
calc_NumberOfCellsX(BasicParams.SystemSizeX),
calc_NumberOfCellsY(BasicParams.SystemSizeY))));
reorder<<<grid, blocks, Ns>>>(CellStart, CellEnd, inPos, outPos, inVel, outVel, inForce, outForce,
inr3dot, outr3dot, inr4dot, outr4dot, inr5dot, outr5dot, inParticleType, outParticleType,
CellId, PId, BasicParams.NumberParticles);
cuda_check_errors(__FILE__, __LINE__);
}
void h_force(const float2* Pos, const float2* Vel, float2* Force,
const unsigned int* CellStart, const unsigned int* CellEnd,
const float2* R,
const unsigned int* ParticleType,
BasicParamsType BasicParams,
unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid)
{
dim3 grid(BlocksPerGrid);
dim3 blocks(ThreadsPerBlock);
force<<<grid, blocks>>>(Pos, Vel, Force, CellStart, CellEnd, R, ParticleType, BasicParams);
cuda_check_errors(__FILE__, __LINE__);
}
template <solver s, boundary b> struct StepperTraits;
template <> struct StepperTraits<euler, periodic>
{
typedef Euler<Pbc> SolverType;
typedef Pbc BoundaryType;
};
template <> struct StepperTraits<euler, lees_edwards>
{
typedef Euler<LeesEdwards> SolverType;
typedef LeesEdwards BoundaryType;
};
template <> struct StepperTraits<gear, periodic>
{
typedef Gear<Pbc> SolverType;
typedef Pbc BoundaryType;
};
template <> struct StepperTraits<gear, lees_edwards>
{
typedef Gear<LeesEdwards> SolverType;
typedef LeesEdwards BoundaryType;
};
template <solver s, boundary b>
void _integrate(float2* Pos, float2* Vel, float2* Force,
float2* r3dot, float2* r4dot, float2* r5dot, float2* Force_predict,
const unsigned int* CellStart, const unsigned int* CellEnd,
const float2* R,
const unsigned int* ParticleType,
const BasicParamsType &BasicParams,
float2* host_Pos, float2* host_Vel, float2* host_Force, int flag,
unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid, float time)
{
dim3 grid(BlocksPerGrid);
dim3 blocks(ThreadsPerBlock);
cudaThreadSynchronize();
if (flag == 0)
{
cudaMemcpy((void *)host_Pos,(void *)Pos, BasicParams.NumberParticles*sizeof(float2), cudaMemcpyDeviceToHost);
cudaMemcpy((void *)host_Vel,(void *)Vel, BasicParams.NumberParticles*sizeof(float2), cudaMemcpyDeviceToHost);
cudaMemcpy((void *)host_Force,(void *)Force, BasicParams.NumberParticles*sizeof(float2), cudaMemcpyDeviceToHost);
}
integrate<typename StepperTraits<s, b>::SolverType, typename StepperTraits<s, b>::BoundaryType><<<grid, blocks>>>(Pos, Vel, Force,
r3dot, r4dot, r5dot, Force_predict,
CellStart, CellEnd,
BasicParams, time);
cuda_check_errors(__FILE__, __LINE__);
}
template <solver s, boundary b>
void _predict(float2* Pos, float2* Vel, float2* Force,
float2* r3dot, float2* r4dot, float2* r5dot, float2* Force_predict,
const BasicParamsType &BasicParams,
unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid, float time)
{
dim3 grid(BlocksPerGrid);
dim3 blocks(ThreadsPerBlock);
typedef typename StepperTraits<s, b>::SolverType SolverType;
typedef typename StepperTraits<s, b>::BoundaryType BoundaryType;
predict<SolverType, BoundaryType><<<grid, blocks>>>
(Pos, Vel,
Force,
r3dot, r4dot,
r5dot,
Force_predict,
BasicParams,
time);
cuda_check_errors(__FILE__, __LINE__);
}
template <> void
StepperScheme<euler, periodic>::h_integrate(float2* Pos, float2* Vel, float2* Force,
float2* r3dot, float2* r4dot, float2* r5dot, float2* Force_predict,
const unsigned int* CellStart, const unsigned int* CellEnd,
const float2* R,
const unsigned int* ParticleType,
const BasicParamsType &BasicParams,
float2* host_Pos, float2* host_Vel, float2* host_Force, int flag,
unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid, float time)
{
h_force(Pos, Vel, Force, CellStart, CellEnd, R, ParticleType, BasicParams, ThreadsPerBlock, BlocksPerGrid);
_integrate<euler, periodic>(Pos, Vel, Force,
r3dot, r4dot, r5dot, Force_predict,
CellStart, CellEnd,
R,
ParticleType,
BasicParams,
host_Pos, host_Vel, host_Force, flag,
ThreadsPerBlock, BlocksPerGrid, time);
cuda_check_errors(__FILE__, __LINE__);
}
template <> void
StepperScheme<gear, periodic>::h_integrate(float2* Pos, float2* Vel, float2* Force,
float2* r3dot, float2* r4dot, float2* r5dot, float2* Force_predict,
const unsigned int* CellStart, const unsigned int* CellEnd,
const float2* R,
const unsigned int* ParticleType,
const BasicParamsType &BasicParams,
float2* host_Pos, float2* host_Vel, float2* host_Force, int flag,
unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid, float time)
{
_predict<gear, periodic>(Pos, Vel,
Force,
r3dot, r4dot,
r5dot,
Force_predict,
BasicParams,
ThreadsPerBlock, BlocksPerGrid, time);
cudaThreadSynchronize();
h_force(Pos, Vel, Force, CellStart, CellEnd, R, ParticleType, BasicParams, ThreadsPerBlock, BlocksPerGrid);
_integrate<gear, periodic>(Pos, Vel, Force,
r3dot, r4dot, r5dot, Force_predict,
CellStart, CellEnd,
R,
ParticleType,
BasicParams,
host_Pos, host_Vel, host_Force, flag,
ThreadsPerBlock, BlocksPerGrid, time);
cuda_check_errors(__FILE__, __LINE__);
}
template <> void
StepperScheme<euler, lees_edwards>::h_integrate(float2* Pos, float2* Vel, float2* Force,
float2* r3dot, float2* r4dot, float2* r5dot, float2* Force_predict,
const unsigned int* CellStart, const unsigned int* CellEnd,
const float2* R,
const unsigned int* ParticleType,
const BasicParamsType &BasicParams,
float2* host_Pos, float2* host_Vel, float2* host_Force, int flag,
unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid, float time)
{
h_force(Pos, Vel, Force, CellStart, CellEnd, R, ParticleType, BasicParams, ThreadsPerBlock, BlocksPerGrid);
_integrate<euler, lees_edwards>(Pos, Vel, Force,
r3dot, r4dot, r5dot, Force_predict,
CellStart, CellEnd,
R,
ParticleType,
BasicParams,
host_Pos, host_Vel, host_Force, flag,
ThreadsPerBlock, BlocksPerGrid, time);
cuda_check_errors(__FILE__, __LINE__);
}
template <> void
StepperScheme<gear, lees_edwards>::h_integrate(float2* Pos, float2* Vel, float2* Force,
float2* r3dot, float2* r4dot, float2* r5dot, float2* Force_predict,
const unsigned int* CellStart, const unsigned int* CellEnd,
const float2* R,
const unsigned int* ParticleType,
const BasicParamsType &BasicParams,
float2* host_Pos, float2* host_Vel, float2* host_Force, int flag,
unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid, float time)
{
_predict<gear, lees_edwards>(Pos, Vel, Force,
r3dot, r4dot, r5dot, Force_predict,
BasicParams,
ThreadsPerBlock, BlocksPerGrid, time);
cudaThreadSynchronize();
h_force(Pos, Vel, Force, CellStart, CellEnd, R, ParticleType, BasicParams, ThreadsPerBlock, BlocksPerGrid);
_integrate<gear, lees_edwards>(Pos, Vel, Force,
r3dot, r4dot, r5dot, Force_predict,
CellStart, CellEnd,
R,
ParticleType,
BasicParams,
host_Pos, host_Vel, host_Force, flag,
ThreadsPerBlock, BlocksPerGrid, time);
cuda_check_errors(__FILE__, __LINE__);
}
#ifndef MDSolver_STEP_13_H
#define MDSolver_STEP_13_H
#include <cutil_inline.h>
#include <map>
#include "cuda_kernel_wrapper_step-13.cu.h"
#include <QString>
#include <QRegExp>
#include <base/parameter_handler.h>
namespace step13 {
struct SimulationParams : public BasicParamsType {
static void declare(::ParameterHandler &prm);
void get(:: ParameterHandler &prm);
ParticleTypeSpecs ParticleSpecs;
};
void SimulationParams::declare(::ParameterHandler &prm)
{
prm.declare_entry("Configuration",
"rnd",
::Patterns::Anything(),
"Specifies the CONF"
);
prm.declare_entry("Boundary Condition",
"periodic",
::Patterns::Anything(),
"Specifies the BC"
);
prm.declare_entry("Solver",
"euler",
::Patterns::Anything(),
"Specifies the Solver"
);
prm.declare_entry("SystemSizeX",
"16",
::Patterns::Double(),
"Specifies the SystemSize in x-direction"
);
prm.declare_entry("SystemSizeY",
"16",
::Patterns::Double(),
"Specifies the SystemSize in y-direction"
);
prm.declare_entry("Time",
"2.0",
::Patterns::Double(),
"Specifies the desired simulation time"
);
prm.declare_entry("TimeStep",
"0.1",
::Patterns::Double(),
"Specifies the time-step"
);
prm.declare_entry("Seed",
"1",
::Patterns::Integer(),
"Specifies the seed for the PRNG"
);
prm.declare_entry("Measure",
"10",
::Patterns::Integer(),
"Specifies the number of timesteps between measurements"
);
prm.declare_entry("Fileout",
"output",
::Patterns::Anything(),
"Specifies the name of an outputfile: output_measured-timestep.dat; write \"none\" for no output"
);
prm.declare_entry("ParticlesType",
"<N=1000,r=0.5,m=1>",
::Patterns::Anything(),
"Specifies the parameters of the particles"
);
}
void SimulationParams::get(::ParameterHandler &prm)
{
typedef std::map<std::string, particleconfig> PC_NAME2ENUM;
PC_NAME2ENUM pc_name2enum;
pc_name2enum["rnd"]=rnd;
pc_name2enum["conf"]=conf;
PC_NAME2ENUM::const_iterator pc = pc_name2enum.find(prm.get("Configuration"));
if (pc != pc_name2enum.end())
PConf = pc->second;
else
{
std::cerr << "Illegal value for Particle Configuration. Check prm-file" << std::endl;
exit(-1);
}
typedef std::map<std::string, boundary> BC_NAME2ENUM;
BC_NAME2ENUM bc_name2enum;
bc_name2enum["periodic"]=periodic;
bc_name2enum["lees_edwards"]=lees_edwards;
BC_NAME2ENUM::const_iterator bc = bc_name2enum.find(prm.get("Boundary Condition"));
if (bc != bc_name2enum.end())
this->boundary_conditions = bc->second;
else
{
std::cerr << "Illegal value for Boundary Condition. Check prm-file" << std::endl;
exit(-1);
}
typedef std::map<std::string, solver> S_NAME2ENUM;
S_NAME2ENUM s_name2enum;
s_name2enum["euler"]=euler;
s_name2enum["gear"]=gear;
S_NAME2ENUM::const_iterator s = s_name2enum.find(prm.get("Solver"));
if (s != s_name2enum.end())
SolverType = s->second;
else
{
std::cerr << "Illegal value for Solver. Check prm-file" << std::endl;
exit(-1);
}
SystemSizeX = prm.get_double("SystemSizeX");
SystemSizeY = prm.get_double("SystemSizeY");
Time = prm.get_double("Time");
TimeStep = prm.get_double("TimeStep");
Seed = prm.get_integer("Seed");
measure = prm.get_integer("Measure");
fileout = prm.get("Fileout").c_str();
QString Q_ParticlesType(prm.get("ParticlesType").c_str());
QRegExp Q_ParticlesSeperator(">\\s*<");
unsigned int NumberOfSpecies = Q_ParticlesType.count(Q_ParticlesSeperator) + 1;
QRegExp Q_GetRadius("r=[0-9]*\\x002E{0,1}[0-9]*");
QRegExp Q_GetMass("m=[0-9]*\\x002E{0,1}[0-9]*");
QRegExp Q_GetNumber("N=[0-9]*");
QRegExp Q_GetFloat("(.{1,}=)([0-9]*\\x002E{0,1}[0-9]*)");
QRegExp Q_GetInt("(.{1,}=)([0-9]*)");
if (NumberOfSpecies == 0)
{
printf("Error: a simulation without particles?");
exit(-1);
}
else
{
ParticleSpecs.Reinit(NumberOfSpecies);
for (unsigned int zaehler=0; zaehler<NumberOfSpecies; zaehler++)
{
int posN1 = Q_GetNumber.indexIn(Q_ParticlesType.section(Q_ParticlesSeperator, zaehler, zaehler, QString::SectionSkipEmpty));
int posN2 = Q_GetInt.indexIn(Q_GetNumber.cap(0));
ParticleSpecs.Number[zaehler] = Q_GetInt.cap(2).toInt();
int posR1 = Q_GetRadius.indexIn(Q_ParticlesType.section(Q_ParticlesSeperator, zaehler, zaehler, QString::SectionSkipEmpty));
int posR2 = Q_GetFloat.indexIn(Q_GetRadius.cap(0));
ParticleSpecs.Radius[zaehler] = Q_GetFloat.cap(2).toFloat();
int posM1 = Q_GetMass.indexIn(Q_ParticlesType.section(Q_ParticlesSeperator, zaehler, zaehler, QString::SectionSkipEmpty));
int posM2 = Q_GetFloat.indexIn(Q_GetMass.cap(0));
ParticleSpecs.Mass[zaehler] = Q_GetFloat.cap(2).toFloat();
}
}
NumberParticles=0;
for (unsigned int zaehler=0; zaehler<NumberOfSpecies; zaehler++)
{
NumberParticles+=ParticleSpecs.Number[zaehler];
}
}
class MDBase {
public:
virtual void run() = 0;
unsigned int BlocksPerGrid;
unsigned int ThreadsPerBlock;
};
template <solver s, boundary b>
class MDSolver : public MDBase {
public:
MDSolver(const BasicParamsType &BasicParams, const ParticleTypeSpecs &ParticleSpecs);
virtual void run();
private:
const BasicParamsType *BasicParams;
const ParticleTypeSpecs *ParticleSpecs;
};
} // namespace step13 END
#endif // MDSolver_STEP_13_H
#ifndef CUDA_DRIVER_STEP_13_HH
#define CUDA_DRIVER_STEP_13_HH
#include "cuda_driver_step-13.h"
#include "particles_step-13.h"
#include "cuda_kernel_wrapper_step-13.cu.h"
#include <ctime>
template <solver s, boundary b>
step13::MDSolver<s, b>::MDSolver(const BasicParamsType &Params,
const ParticleTypeSpecs &ParticleSpecs)
: BasicParams(&Params),ParticleSpecs(&ParticleSpecs)
{
ThreadsPerBlock = 256;
BlocksPerGrid = static_cast<unsigned int>
(ceil(static_cast<float>(Params.NumberParticles)
/static_cast<float>(ThreadsPerBlock)));
}
template <solver s, boundary b>
void step13::MDSolver<s, b>::run()
{
unsigned int stepnumber=0;
clock_t timerA=clock();
clock_t timerB;
printf("Start \n");
Particles<s, b> p(*BasicParams, *ParticleSpecs);
cuda_check_errors(__FILE__, __LINE__);
printf("TeilchenSystem angelegt \n");
for (float time=0.0; time < BasicParams->Time; time += BasicParams->TimeStep )
{
p._calc_id(ThreadsPerBlock, BlocksPerGrid);
cuda_check_errors(__FILE__, __LINE__);
cudaThreadSynchronize();
/ *printf("CellIds berechnet \n");* /
p._sort();
cuda_check_errors(__FILE__, __LINE__);
/ *printf("Daten vorsortiert \n");* /
p._reorder(ThreadsPerBlock, BlocksPerGrid);
cudaThreadSynchronize();
p._copy_sorted_data();
/ *printf("Daten sortiert \n");* /
cudaThreadSynchronize();
p._integrate(ThreadsPerBlock, BlocksPerGrid, stepnumber % BasicParams->measure, time);
cudaThreadSynchronize();
/ *printf("Integriert \n");* /
timerB = clock();
if (stepnumber % BasicParams->measure == 0)
{
p.put_out(time);
cuda_check_errors(__FILE__, __LINE__);
}
stepnumber++;
}
std::cout << (double)(timerB-timerA)/(double)(CLOCKS_PER_SEC) << std::endl;
}
#endif // CUDA_DRIVER_STEP_13_HH
#ifndef INTEGRATION_STEP_13_H
#define INTEGRATION_STEP_13_H
#define c0 0.1875
#define c1 0.697222222222
#define c2 1.0
#define c3 0.611111111111
#define c4 0.166666666667
#define c5 0.0166666666667
__global__ void calcid(const float2* pos, unsigned int *CellId, unsigned int *PId, BasicParamsType BasicParams);
__global__ void reorder(unsigned int *CellStart, unsigned int *CellEnd,
float2 *inPos, float2 *outPos, float2 *inVel, float2 *outVel, float2* inForce, float2* outForce,
float2* inr3dot, float2* outr3dot, float2* inr4dot , float2* outr4dot, float2* inr5dot, float2* outr5dot,
unsigned int* inParticleType, unsigned int* outParticleType,
unsigned int *CellId, unsigned int *PId, unsigned int NumberParticles);
template<typename Stepper, typename Boundary> __global__ void integrate(float2* Pos, float2* Vel, float2* Force,
float2* r3dot, float2* r4dot, float2* r5dot, float2* Force_predict,
const unsigned int* CellStart, const unsigned int* CellEnd,
BasicParamsType BasicParams,
Stepper propagate,
float time);
__device__ void check_boundary(float2* Pos, float lx, float ly);
__global__ void force(const float2* Pos, const float2* Vel, float2* Force,
const unsigned int* CellStart, const unsigned int* CellEnd,
const float2* R,
const unsigned int* ParticleType,
BasicParamsType BasicParams);
__device__ float2 calc_force(unsigned int index, int2 shift, const float2* Pos, const float2* Vel,
const unsigned int* CellStart, const unsigned int* CellEnd,
float2* R, unsigned int* ParticleType,
BasicParamsType BasicParams);
__device__ float2 collide(float2 posa, float2 vela, float2 posb, float2 velb, const float2* R, const unsigned int* ParticleType, const unsigned int index, const unsigned int count, const float lx, const float ly);
__device__ float Overlap(const float2 pa, const float2 pb, const float r1, const float r2, const float lx, const float ly, int2* sign);
__device__ float2 RelVel(const float2 pa, const float2 pb);
__device__ int shifts(int d, float l);
__device__ uint2 getCell(float2 pos);
__device__ unsigned int calc_single_CellId(int2 shift, float SystemSizeX,float SystemSizeY);
#endif //INTEGRATION_STEP_13_H
#include "integration_step-13.h"
#include "cutil_math.h"
__global__ void calcid(const float2 *pos, unsigned int *CellId, unsigned int *PId,
BasicParamsType BasicParams)
{
unsigned int index = blockIdx.x*blockDim.x + threadIdx.x;
if (index >= BasicParams.NumberParticles) {return;}
CellId[index] = static_cast<int>(floor(pos[index].x))
+ static_cast<int>(floor(pos[index].y)*ceil(BasicParams.SystemSizeX));
PId[index] = index;
}
__global__ void reorder(unsigned int *CellStart, unsigned int *CellEnd,
float2 *inPos, float2 *outPos, float2 *inVel, float2 *outVel, float2* inForce, float2* outForce,
float2* inr3dot, float2* outr3dot, float2* inr4dot , float2* outr4dot, float2* inr5dot, float2* outr5dot,
unsigned int* inParticleType, unsigned int* outParticleType,
unsigned int *CellId, unsigned int *PId, unsigned int NumberParticles)
{
extern __shared__ unsigned int sharedCellId[];
unsigned int index = blockIdx.x*blockDim.x + threadIdx.x;
unsigned int cellid;
if (index < NumberParticles)
{
cellid = CellId[index];
sharedCellId[threadIdx.x+1] = cellid;
if (index > 0 && threadIdx.x == 0)
{
sharedCellId[0] = CellId[index-1];
}
}
__syncthreads();
if (index < NumberParticles)
{
if (index == 0 || cellid != sharedCellId[threadIdx.x])
{
CellStart[cellid] = index;
if (index > 0)
CellEnd[sharedCellId[threadIdx.x]] = index;
}
if (index == NumberParticles -1)
{
CellEnd[cellid] = index + 1;
}
unsigned int sortedPId = PId[index];
outPos[index] = inPos[sortedPId];
outVel[index] = inVel[sortedPId];
outForce[index] = inForce[sortedPId];
outr3dot[index] = inr3dot[sortedPId];
outr4dot[index] = inr4dot[sortedPId];
outr5dot[index] = inr5dot[sortedPId];
outParticleType[index] = inParticleType[sortedPId];
}
}
__device__ uint2 getCell(float2 pos)
{
return make_uint2(floor(pos.x),floor(pos.y));
}
__device__ unsigned int calc_single_CellId(int2 shift, float SystemSizeX,float SystemSizeY)
{
return static_cast<unsigned int>(shift.x)
%static_cast<unsigned int>(ceil(SystemSizeX))
+ (static_cast<unsigned int>(shift.y)
%static_cast<unsigned int>(ceil(SystemSizeY)))*static_cast<unsigned int>(ceil(SystemSizeX));
}
__device__ float Overlap(const float2 pa, const float2 pb, const float r1, const float r2, const float lx, const float ly, int2* sign)
{
float dx = pa.x - pb.x;
if (dx > lx-(1.0+1.0)) {dx -=lx; sign->x*=-1;}
else if (dx < -lx+(1.0+1.0)) {dx +=lx; sign->x*=-1;}
float dy = pa.y - pb.y;
if (dy > ly-(1.0+1.0)) {dy -=ly; sign->y*=-1;}
else if (dy < -ly+(1.0+1.0)) {dy +=ly; sign->y*=-1;}
float local_overlap = r1 + r2 - sqrt(dx*dx+dy*dy);
return local_overlap;
}
__device__ float2 RelVel(const float2 pa, const float2 pb)
{
float dvx = pa.x-pb.x;
float dvy = pa.y-pb.y;
return make_float2(dvx, dvy);
}
__device__ int shifts(int d, float l)
{
if (d < 0) {d += static_cast<int>(ceil(l));}
else if (d >= l) {d -= static_cast<int>(ceil(l));}
return d;
}
__device__ float2 collide(float2 posa, float2 vela, float2 posb, float2 velb, const float2* R,
const unsigned int* ParticleType,
const unsigned int index, const unsigned int count,
const float lx, const float ly)
{
int2 sign=make_int2(1,1);
float2 force_local=make_float2(0,0);
float local_overlap=Overlap(posa, posb, R[ParticleType[index]].x, R[ParticleType[count]].x, lx, ly, &sign);
if (local_overlap > 0.0)
{
force_local += RelVel(velb, vela);
force_local -= local_overlap*make_float2(sign)*normalize(posb-posa);
}
return force_local*(R[ParticleType[index]].y*R[ParticleType[count]].y)/(R[ParticleType[index]].y+R[ParticleType[count]].y);
}
__device__ float2 calc_force(unsigned int index, int2 shift,
const float2* Pos, const float2* Vel,
const unsigned int* CellStart, const unsigned int* CellEnd,
const float2* R,
const unsigned int* ParticleType,
BasicParamsType BasicParams)
{
float2 force_local= make_float2(0,0);
unsigned int cellid = calc_single_CellId(shift, BasicParams.SystemSizeX, BasicParams.SystemSizeY);
unsigned int startIndex = CellStart[cellid];
if (startIndex != 0xffffffff)
{
unsigned int endIndex = CellEnd[cellid];
for (unsigned int count=startIndex; count < endIndex; count++)
{
if(count != index)
{
force_local += collide(Pos[index], Vel[index], Pos[count], Vel[count], R, ParticleType, index, count, BasicParams.SystemSizeX, BasicParams.SystemSizeY);
}
}
}
return force_local;
}
__global__ void force(const float2* Pos, const float2* Vel, float2* Force,
const unsigned int* CellStart, const unsigned int* CellEnd,
const float2* R,
const unsigned int* ParticleType,
BasicParamsType BasicParams)
{
unsigned int index = blockIdx.x*blockDim.x + threadIdx.x;
if (index >= BasicParams.NumberParticles) { return; }
float2 pos = Pos[index];
uint2 gridpos = getCell(pos);
float2 force_local = make_float2(0,0);
for (int y=-1; y <=1; y++ )
{
for (int x=-1; x <=1; x++ )
{
int2 shift = make_int2(x,y) + make_int2(gridpos.x,gridpos.y);
shift.x = shifts(shift.x, BasicParams.SystemSizeX);
shift.y = shifts(shift.y, BasicParams.SystemSizeY);
force_local += calc_force(index, shift, Pos, Vel, CellStart, CellEnd, R, ParticleType, BasicParams);
}
}
Force[index] = force_local;
}
__device__ void check_boundary(float2* Pos, float lx, float ly)
{
if (Pos->x < 0.0) {Pos->x+=lx;}
else if (Pos->x > lx) {Pos->x-=lx;}
if (Pos->y < 0.0) {Pos->y+=ly;}
else if (Pos->y > ly) {Pos->y-=ly;}
}
class Pbc {
public:
__device__ Pbc() {}
__device__ __forceinline__ void operator() (float2* Pos,
float2* Vel,
float lx,
float ly,
float time) const
{
if (Pos->x < 0.0) {Pos->x+=lx;}
else if (Pos->x > lx) {Pos->x-=lx;}
if (Pos->y < 0.0) {Pos->y+=ly;}
else if (Pos->y > ly) {Pos->y-=ly;}
}
};
class LeesEdwards {
public:
__device__ LeesEdwards()
:
__g(4.0)
{}
__device__ __forceinline__ void operator() (float2* Pos,
float2* Vel,
float lx,
float ly,
float time) const
{
if (Pos->y < 0.0) {Pos->y+=ly; Pos->x+=time*__g; Vel->x+=__g;}
else if (Pos->y > ly) {Pos->y-=ly; Pos->x-=time*__g; Vel->x-=__g;}
if (Pos->x < 0.0) {Pos->x = fmod(Pos->x, lx); Pos->x +=lx;}
if (Pos->x > lx) {Pos->x= fmod(Pos->x, lx);}
}
private:
float __g;
};
template <typename Boundary>
class Euler {
public:
__device__ Euler(float dt)
:
__dt(dt)
{}
__device__ __forceinline__ void operator() (unsigned int index,
float2& pos_local,
float2& vel_local,
const float2* Pos,
float2* Vel,
float2* Force,
float2* r3dot,
float2* r4dot,
float2* r5dot,
float2* Force_predict,
const unsigned int* CellStart,
const unsigned int* CellEnd,
Boundary apply_boundary,
const BasicParamsType BasicParams,
float time) const
{
pos_local = pos_local + vel_local * __dt;
apply_boundary(&pos_local, &vel_local,
BasicParams.SystemSizeX,
BasicParams.SystemSizeY,
time);
vel_local = vel_local + Force[index] * __dt;
}
private:
float __dt;
};
template <typename Boundary>
class Gear {
public:
__device__ Gear(float dt) : __dt(dt)
{
}
__device__ __forceinline__ void operator() (unsigned int index,
float2& pos_local,
float2& vel_local,
float2* Pos,
float2* Vel,
float2* Force,
float2* r3dot,
float2* r4dot,
float2* r5dot,
float2* Force_predict,
const unsigned int* CellStart,
const unsigned int* CellEnd,
Boundary apply_boundary,
const BasicParamsType BasicParams,
float time) const
{
float a1 = __dt;
float a2 = a1*__dt/2.0;
float a3 = a2*__dt/3.0;
float b0 = c0 * a2;
float b1 = c1 * a1 / 2.0;
float b2 = c2;
float b3 = c3 / (3.0*__dt);
float b4 = c4 * 6.0 / (a2);
float b5 = c5 * 2.5 / (a3);
float2 corr = Force[index] - Force_predict[index];
pos_local += b0 * corr;
apply_boundary(&pos_local, &vel_local, BasicParams.SystemSizeX, BasicParams.SystemSizeY, time);
vel_local += b1 * corr;
Force[index] = Force_predict[index] + b2*corr;
r3dot[index] += b3 * corr;
r4dot[index] += b4 * corr;
r5dot[index] += b5 * corr;
}
private:
float __dt;
};
template<typename Stepper, typename Boundary>
__global__ void predict(float2* Pos, float2* Vel,
float2* Force,
float2* r3dot, float2* r4dot,
float2* r5dot,
float2* Force_predict,
BasicParamsType BasicParams,
float time)
{
unsigned int index = blockIdx.x*blockDim.x + threadIdx.x;
if (index >= BasicParams.NumberParticles) {return;}
Boundary apply_boundary;
float dt = BasicParams.TimeStep;
float a1 = dt;
float a2 = a1*dt/2.0;
float a3 = a2*dt/3.0;
float a4 = a3*dt/4.0;
float a5 = a4*dt/5.0;
Pos[index] += a1*Vel[index] + a2*Force[index] + a3*r3dot[index] + a4*r4dot[index] + a5*r5dot[index];
apply_boundary(&Pos[index], &Vel[index],BasicParams.SystemSizeX, BasicParams.SystemSizeY, time);
Vel[index] += a1*Force[index] + a2*r3dot[index] + a3*r4dot[index] + a4*r5dot[index];
Force_predict[index] = Force[index] + a1*r3dot[index] + a2*r4dot[index] + a3*r5dot[index];
r3dot[index] += a1*r4dot[index] + a2*r5dot[index];
r4dot[index] += a1*r5dot[index];
}
template<typename Stepper, typename Boundary>
__global__ void integrate(float2* Pos, float2* Vel, float2* Force,
float2* r3dot, float2* r4dot, float2* r5dot, float2* Force_predict,
const unsigned int* CellStart, const unsigned int* CellEnd,
BasicParamsType BasicParams,
float time)
{
Stepper propagate(BasicParams.TimeStep);
Boundary apply_boundary;
unsigned int index = blockIdx.x*blockDim.x + threadIdx.x;
if (index >= BasicParams.NumberParticles) {return;}
float2 pos_local = Pos[index];
float2 vel_local = Vel[index];
propagate(index,
pos_local, vel_local,
Pos, Vel, Force,
r3dot, r4dot, r5dot, Force_predict,
CellStart, CellEnd,
apply_boundary,
BasicParams,
time);
Pos[index] = pos_local;
Vel[index] = vel_local;
}
#ifndef PARTICLES_STEP_13_H
#define PARTICLES_STEP_13_H
#include <iostream>
#include <cstdlib>
#include <fstream>
#include <vector>
#include <QString>
#include <QRegExp>
#include <cstring>
#include <thrust/device_vector.h>
#include <thrust/host_vector.h>
#include "cuda_kernel_wrapper_step-13.cu.h"
using namespace std;
ostream & operator <<(ostream &os, const float2 data); // DER KAN NWEG; DAS DEN OPERATOR SCHON IN cublas_vector.h GIBT!!!
ifstream & operator >>(ifstream &is, float2* data);
template<solver s, boundary b>
class Particles {
public:
typedef thrust::host_vector<float2> ParticleDataContainerHost;
typedef thrust::device_vector<float2> ParticleDataContainerDev;
typedef thrust::host_vector<unsigned int> IndexArrayHost;
typedef thrust::device_vector<unsigned int> IndexArray;
Particles(const BasicParamsType &Params, const ParticleTypeSpecs &ParticleSpecs)
:BasicParams(&Params),ParticleSpecs(&ParticleSpecs)
{
init_particles();
}
~Particles()
{
finalize_particles();
}
void init_particles();
void finalize_particles();
void put_out(float time);
void read_in();
void _calc_id(unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid)
{
h_calcid(thrust::raw_pointer_cast(&Pos[0]), thrust::raw_pointer_cast(&CellId[0]), thrust::raw_pointer_cast(&PId[0]),
*BasicParams, ThreadsPerBlock, BlocksPerGrid);
}
void _sort()
{
IndexArrayHost host_cell;
IndexArrayHost host_pid;
host_cell.resize(BasicParams->NumberParticles);
host_pid.resize(BasicParams->NumberParticles);
cudaMemcpy((void *)thrust::raw_pointer_cast(&host_cell[0]),(void *)thrust::raw_pointer_cast(&CellId[0]), BasicParams->NumberParticles*sizeof(unsigned int), cudaMemcpyDeviceToHost);
cudaMemcpy((void *)thrust::raw_pointer_cast(&host_pid[0]),(void *)thrust::raw_pointer_cast(&PId[0]), BasicParams->NumberParticles*sizeof(unsigned int), cudaMemcpyDeviceToHost);
sort(thrust::raw_pointer_cast(&host_cell[0]),thrust::raw_pointer_cast(&host_pid[0]), BasicParams->NumberParticles);
cudaMemcpy((void *)thrust::raw_pointer_cast(&CellId[0]),(void *)thrust::raw_pointer_cast(&host_cell[0]), BasicParams->NumberParticles*sizeof(unsigned int), cudaMemcpyHostToDevice);
cudaMemcpy((void *)thrust::raw_pointer_cast(&PId[0]), (void *)thrust::raw_pointer_cast(&host_pid[0]), BasicParams->NumberParticles*sizeof(unsigned int), cudaMemcpyHostToDevice);
}
void _force(unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid)
{
h_force(thrust::raw_pointer_cast(&Pos[0]), thrust::raw_pointer_cast(&Vel[0]), thrust::raw_pointer_cast(&Force[0]),
thrust::raw_pointer_cast(&CellStart[0]), thrust::raw_pointer_cast(&CellEnd[0]),
thrust::raw_pointer_cast(&R[0]),
thrust::raw_pointer_cast(&ParticleType[0]),
*BasicParams, ThreadsPerBlock, BlocksPerGrid);
}
void _reorder(unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid)
{
h_reorder(thrust::raw_pointer_cast(&CellStart[0]), thrust::raw_pointer_cast(&CellEnd[0]), thrust::raw_pointer_cast(&Pos[0]), thrust::raw_pointer_cast(&Pos_sorted[0]),
thrust::raw_pointer_cast(&Vel[0]), thrust::raw_pointer_cast(&Vel_sorted[0]), thrust::raw_pointer_cast(&Force[0]), thrust::raw_pointer_cast(&Force_sorted[0]),
thrust::raw_pointer_cast(&r3dot[0]), thrust::raw_pointer_cast(&r3dot_sorted[0]),
thrust::raw_pointer_cast(&r4dot[0]), thrust::raw_pointer_cast(&r4dot_sorted[0]),
thrust::raw_pointer_cast(&r5dot[0]), thrust::raw_pointer_cast(&r5dot_sorted[0]),
thrust::raw_pointer_cast(&ParticleType[0]), thrust::raw_pointer_cast(&ParticleType_sorted[0]),
thrust::raw_pointer_cast(&CellId[0]), thrust::raw_pointer_cast(&PId[0]), *BasicParams, ThreadsPerBlock, BlocksPerGrid);
}
void _copy_sorted_data()
{
Pos=Pos_sorted; Vel=Vel_sorted; Force=Force_sorted;
r3dot=r3dot_sorted; r4dot=r4dot_sorted; r5dot=r5dot_sorted;
ParticleType = ParticleType_sorted;
}
void _integrate(unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid, int flag, float time);
void _predict(unsigned int ThreadsPerBlock,
unsigned int BlocksPerGrid);
private:
const BasicParamsType *BasicParams;
const ParticleTypeSpecs *ParticleSpecs;
__device__ __constant__ BasicParamsType dev_BasicParams;
ParticleDataContainerDev R;
IndexArray ParticleType;
IndexArray ParticleType_sorted;
ParticleDataContainerDev Pos, Vel, Force, Pos_sorted, Vel_sorted, Force_sorted;
ParticleDataContainerDev r3dot, r4dot, r5dot, Force_predict;
ParticleDataContainerDev r3dot_sorted, r4dot_sorted, r5dot_sorted;
IndexArray PId, CellId, CellStart, CellEnd;
ParticleDataContainerHost host_Pos, host_Vel, host_Force, RHost;
};
template <solver s, boundary b>
void Particles<s, b>::_integrate(unsigned int ThreadsPerBlock, unsigned int BlocksPerGrid, int flag, float time)
{
StepperScheme<s, b>::h_integrate(thrust::raw_pointer_cast(&Pos[0]), thrust::raw_pointer_cast(&Vel[0]), thrust::raw_pointer_cast(&Force[0]),
thrust::raw_pointer_cast(&r3dot[0]), thrust::raw_pointer_cast(&r4dot[0]),
thrust::raw_pointer_cast(&r5dot[0]), thrust::raw_pointer_cast(&Force_predict[0]),
thrust::raw_pointer_cast(&CellStart[0]), thrust::raw_pointer_cast(&CellEnd[0]),
thrust::raw_pointer_cast(&R[0]),
thrust::raw_pointer_cast(&ParticleType[0]),
*BasicParams,
thrust::raw_pointer_cast(&host_Pos[0]), thrust::raw_pointer_cast(&host_Vel[0]), thrust::raw_pointer_cast(&host_Force[0]), flag,
ThreadsPerBlock, BlocksPerGrid, time);
}
#include "particles_step-13.hh"
#endif //PARTICLES_STEP_13_H
#ifndef PARTICLES_STEP_13_HH
#define PARTICLES_STEP_13_HH
#include "particles_step-13.h"
#include "cutil_inline.h"
#include "thrust/sort.h"
template <solver s, boundary b>
void Particles<s, b>::init_particles()
{
host_Pos.resize(BasicParams->NumberParticles);
host_Vel.resize(BasicParams->NumberParticles);
host_Force.resize(BasicParams->NumberParticles);
ParticleDataContainerHost initializer;
initializer.resize(BasicParams->NumberParticles);
IndexArrayHost ParticleTypeHost;
ParticleTypeHost.resize(BasicParams->NumberParticles);
ParticleType = ParticleTypeHost;
ParticleType_sorted = ParticleTypeHost;
unsigned int type=0;
unsigned int temp_number=0;
for (unsigned int zaehler=0; zaehler<BasicParams->NumberParticles; zaehler++)
{
ParticleTypeHost[zaehler] = type;
if ( ParticleSpecs->Number[type] == zaehler-1)
type++;
}
ParticleType = ParticleTypeHost;
/ *
R.resize(ParticleSpecs->NSpecies);
* /
RHost.resize(ParticleSpecs->NSpecies);
R = RHost;
for (type=0; type<ParticleSpecs->NSpecies; type++)
{
RHost[type].x = ParticleSpecs->Radius[type];
RHost[type].y = ParticleSpecs->Mass[type];
}
R = RHost;
if (BasicParams->PConf == rnd)
{
srand(BasicParams->Seed);
for (unsigned int count=0; count < BasicParams->NumberParticles; count++)
{
host_Pos[count].x = BasicParams->SystemSizeX*
static_cast<float>(rand())/static_cast<float>(RAND_MAX);
host_Pos[count].y = BasicParams->SystemSizeY*
static_cast<float>(rand())/static_cast<float>(RAND_MAX);
host_Vel[count].x = -1.0
+2.0*static_cast<float>(rand())/static_cast<float>(RAND_MAX);
/ *host_Vel[count].y = -1.0
+2.0*static_cast<float>(rand())/static_cast<float>(RAND_MAX);* /
host_Vel[count].y = 0.0;
initializer[count].x = 0.0;
initializer[count].y = 0.0;
host_Force[count].x = 0.0;
host_Force[count].y = 0.0;
}
}
if (BasicParams->PConf == conf)
{
float2 R_temp;
ifstream infile ("conf.test");
for (unsigned int count=0; count < BasicParams->NumberParticles; count++)
{
if (infile.good())
{
infile >> &host_Pos[count] >> &host_Vel[count] >> &host_Force[count] >> &R_temp;
for (type=0; type<ParticleSpecs->NSpecies; type++)
{
if (RHost[type].x == R_temp.x && RHost[type].y == R_temp.y)
ParticleTypeHost[count] = type;
}
}
else
{
std::cerr << "Error while reading configuration" << std::endl;
exit(-1);
}
initializer[count].x = 0.0;
initializer[count].y = 0.0;
}
ParticleType = ParticleTypeHost;
infile.close();
}
Pos = host_Pos;
Vel = host_Vel;
Force = host_Force;
/ *Pos_sorted.resize(Pos.size());
Vel_sorted.resize(Vel.size());
Force_sorted.resize(Force.size());* /
Pos_sorted = initializer;
Vel_sorted = initializer;
Force_sorted = initializer;
/ *r3dot.resize(Pos.size());
r4dot.resize(Pos.size());
r5dot.resize(Pos.size());
Force_predict.resize(Pos.size());* /
r3dot = initializer;
r4dot = initializer;
r5dot = initializer;
Force_predict = initializer;
r3dot = initializer;
r4dot = initializer;
r5dot = initializer;
Force_predict = initializer;
/ *
r3dot_sorted.resize(Pos.size());
r4dot_sorted.resize(Pos.size());
r5dot_sorted.resize(Pos.size());
* /
r3dot_sorted = initializer;
r4dot_sorted = initializer;
r5dot_sorted = initializer;
unsigned int NumCellsX = calc_NumberOfCellsX(BasicParams->SystemSizeX);
unsigned int NumCellsY = calc_NumberOfCellsY(BasicParams->SystemSizeY);
unsigned int NumberOfCells=calc_NumberOfCells(NumCellsX, NumCellsY);
IndexArrayHost init_int;
init_int.resize(NumberOfCells);
CellStart = init_int;
CellEnd = init_int;
/ *
CellStart.resize(NumberOfCells);
CellEnd.resize(NumberOfCells);
* /
init_int.resize(BasicParams->NumberParticles);
PId = init_int;
CellId = init_int;
/ *
PId.resize(BasicParams->NumberParticles);
CellId.resize(BasicParams->NumberParticles);
* /
}
template <solver s, boundary b>
void Particles<s, b>::finalize_particles()
{
}
void sort(unsigned int* CellId, unsigned int* PId, unsigned int NumElements)
{
thrust::sort_by_key(CellId, CellId + NumElements, PId);
}
ostream & operator <<(ostream &os, const float2 data)
{
os << data.x << "\t" << data.y;
return os;
}
ifstream & operator >>(ifstream &is, float2* data)
{
is >> data->x >> data->y;
return is;
}
template <solver s, boundary b>
void Particles<s, b>::put_out(float time)
{
float px=0.0;
float py=0.0;
float ekin=0.0;
ParticleDataContainerHost RHost=R;
IndexArrayHost ParticleTypeHost=ParticleType;
if ( QString::compare(QString(BasicParams->fileout),QString("none")))
{
QString filename((BasicParams->fileout));
QString Q_Time;
Q_Time.setNum(time,'f',6);
filename.append("_");
filename.append(Q_Time);
filename.append(".dat");
std::ofstream fileout;
fileout.open(filename.toStdString().c_str());
fileout.setf(ios::fixed, ios::floatfield);
for (size_t i=0; i < BasicParams->NumberParticles; i++)
{
px += host_Vel[i].x;
py += host_Vel[i].y;
ekin += host_Vel[i].x*host_Vel[i].x + host_Vel[i].y*host_Vel[i].y;
{
fileout << host_Pos[i] << "\t" << host_Vel[i] << "\t" << host_Force[i] << "\t" << RHost[ParticleTypeHost[i]] << endl;
}
}
fileout.close();
}
else
{
for (size_t i=0; i < BasicParams->NumberParticles; i++)
{
px += host_Vel[i].x;
py += host_Vel[i].y;
ekin += host_Vel[i].x*host_Vel[i].x + host_Vel[i].y*host_Vel[i].y;
}
}
cout << time << "\t" << px << "\t" << py << "\t" << ekin << endl;
}
unsigned int calc_NumberOfCellsX(float SystemSizeX)
{
return static_cast<unsigned int>(ceil(SystemSizeX));
}
unsigned int calc_NumberOfCellsY(float SystemSizeY)
{
return static_cast<unsigned int>(ceil(SystemSizeY));
}
unsigned int calc_NumberOfCells(unsigned int NumberOfCellsX,unsigned int NumberOfCellsY)
{
return NumberOfCellsX*NumberOfCellsY;
}
#endif //PARTICLES_STEP_13_HH
#include <iostream>
#include <vector>
#include "cuda_driver_step-13.h"
#include "cuda_driver_step-13.hh"
#define USE_DEAL_II
#undef USE_DEAL_II
namespace step13 {
class MyFancySimulation {
public:
MyFancySimulation(::ParameterHandler &prm_handler);
~MyFancySimulation();
void run();
private:
SimulationParams params;
MDBase * mdbase;
};
}
step13::MyFancySimulation::MyFancySimulation(::ParameterHandler &prm_handler)
{
params.get(prm_handler);
switch (params.SolverType) {
case euler:
if (params.boundary_conditions == periodic)
{
mdbase = new step13::MDSolver<euler, periodic>(params,params.ParticleSpecs);
break;
}
else if (params.boundary_conditions == lees_edwards)
{
mdbase = new step13::MDSolver<euler, lees_edwards>(params,params.ParticleSpecs);
break;
}
else
break;
case gear:
if (params.boundary_conditions == periodic)
{
mdbase = new step13::MDSolver<gear, periodic>(params,params.ParticleSpecs);
break;
}
else if (params.boundary_conditions == lees_edwards)
{
mdbase = new step13::MDSolver<gear, lees_edwards>(params,params.ParticleSpecs);
break;
}
else
break;
default:
break;
}
}
step13::MyFancySimulation::~MyFancySimulation()
{
delete mdbase;
}
void step13::MyFancySimulation::run()
{
mdbase->run();
std::cout << "Fertig." << std::endl;
}
int main(int / *argc* /, char * / *argv* /[])
{
using namespace step13;
::ParameterHandler prm_handler;
SimulationParams::declare(prm_handler);
std::string prm_filename;
prm_filename +="test.prm";
prm_handler.read_input(prm_filename);
MyFancySimulation machma(prm_handler);
machma.run();
}