The step-16 tutorial program
Introduction
The phase retrieval problem is well known, from reconstruction of diffraction images. In this project the Gerchberg-Saxton algorithm is used to calculate the phase-only hologram of a given intensity pattern. This pattern corresponds to a number of neurons, which shall be excited. Using this technique, the dynamics of neural networks shall be investigated.
Experimental Setup
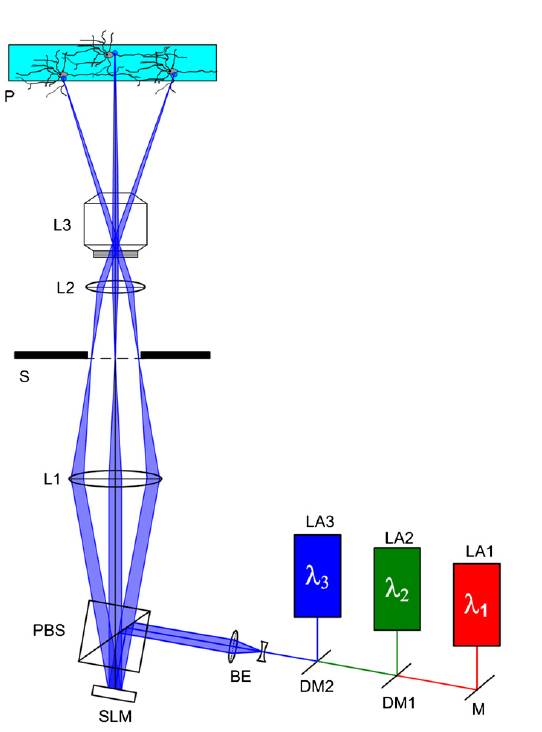
Schematic of the holographic system, from [1]
The figure shows a possible experimental setup for the use of phase holograms.
In the top is a container with neurons. These neurons have special ion channels which open, if they are illuminated. It is possible to measure the excitation pattern of the neurons via electrodes.
The aim is to control the excitation pattern by directed stimulation of single neurons. Various ways have been tried to achieve this, like fiber optics, micro LED arrays or micro mirror devices, but the illumination was not precise enough to excite single neurons.
But with phase holograms it is possible. In order to create different phase holograms, one needs a device which can alter the phase of an incident laser beam. Such a device is called a spatial light modulator (SLM), which works like a LCD-monitor without the polarizing film.
The SLM is evenly illuminated by a laser (this is an important information for the algorithm). The reflected, phaseshifted beam travels through a system of lenses which projects the Fourier transform of the phase pattern of the SLM in the right size onto the neurons eventually stimulating the selected ones.
Some other applications for this kind of setup are, for example, laser tweezers or in a miniaturized version as a retinal prothesis.
Algorithm
The phase holograms are calculated with the Gerchberg-Saxton(GS) algorithm which determines the reconstructed complex field 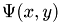 by the following iteration:
by the following iteration:
![\begin{eqnarray} \Psi(x,y)=\lim_{n \to \infty}(\mathcal{P}_m\mathcal{F}^{-1}\mathcal{P}_F\mathcal{F})^n{\left| \Psi(x,y)\exp[i\phi(x,y)] \right|} \end{eqnarray}](form_222.png)
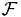 denotes the Fourier transformation and
denotes the Fourier transformation and 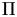 (F-Fourier space, m - real space) a projection operator which adjusts the amplitude, so that the amplitude conditions in the respective realm are fullfilled. The following figure gives a detailed account of the algorithm.
(F-Fourier space, m - real space) a projection operator which adjusts the amplitude, so that the amplitude conditions in the respective realm are fullfilled. The following figure gives a detailed account of the algorithm.
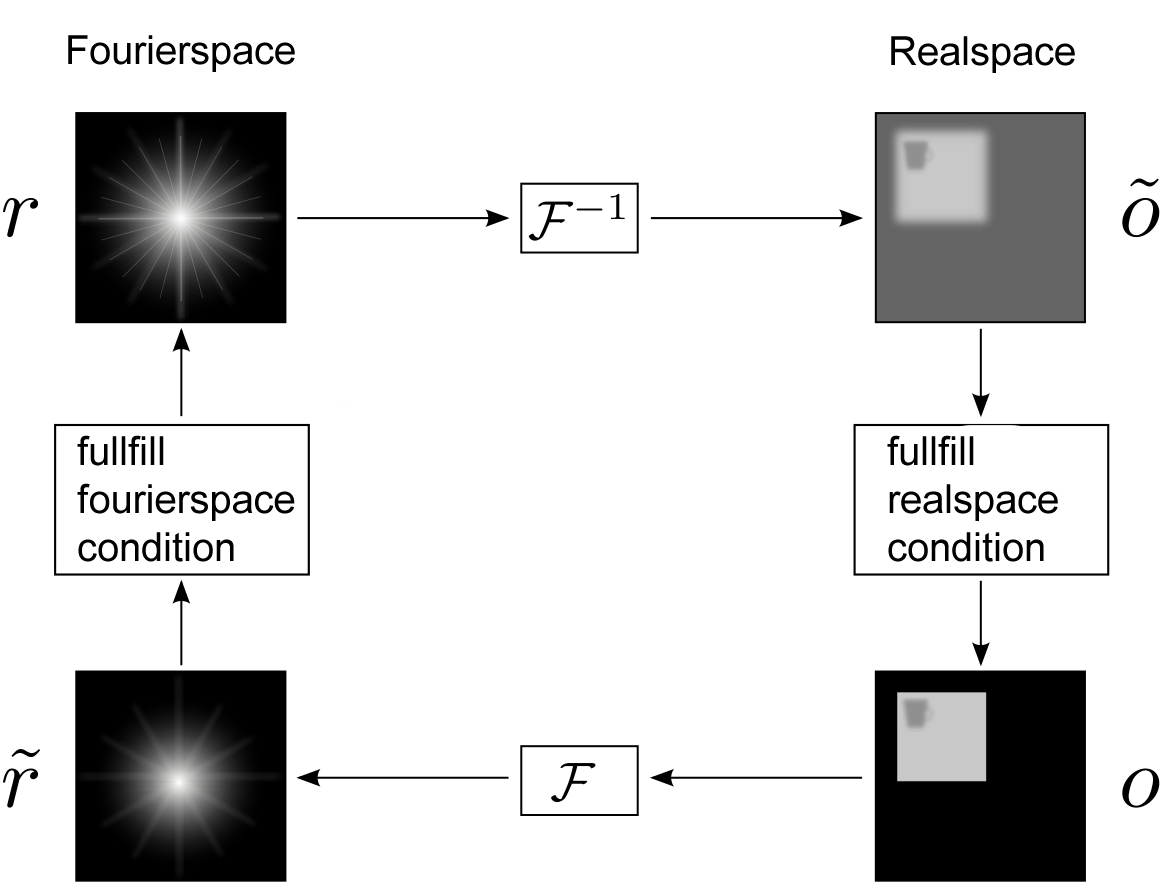
The GS-algorithm
Under the given prerequisites (given real space amplitudes and evenly illuminated Fourier space), we start in the upper right corner. In the first Iteration nothing is to adapt in real space so we can apply directly the Fourier transform to our pattern (if we start in the Fourier space, an initial guess of the phases would be necessary). In Fourier space the amplitudes of the transformed pattern will generally not match with the given ones. We set all amplitudes to the same value, but leave the phases unaltered. Next we transform the pattern back into real space. This completes the first iteration of the algorithm. But now the amplitudes have changed and we must adapt them to match the given pattern. This means we set the modulus of an illuminated pixel to one and of a dark pixel to zero. After that we use the Fourier transformation again and continue as before with amplitude adaption in Fourier space and so on. The algorithm is repeated as long as the convergence criterion is not met or a certain number of iterations is not reached.
The GS-algorithm is straight forward and easy to implement, but it has some flaws, it converges for example to the nearest minimum, which is not necessarily the global minimum of the deviation to the original image. In order to remedy those other issues, modified versions of GS were introduced. This project implements in particular the RAAR-algorithm [6].
Denoting the nth iterate of
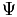 with
with 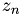 the algorithm can be written in this form:
the algorithm can be written in this form:
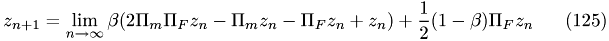
with 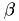 :
:
with  and
and  . One has to choose these values according to the current problem. The RAAR algorithm uses the previous result and some interim results from GS to calculate the next iteration step. The first term in the formula represents the GS step. stands for a projection and Fourier transform in the respective domain.
. One has to choose these values according to the current problem. The RAAR algorithm uses the previous result and some interim results from GS to calculate the next iteration step. The first term in the formula represents the GS step. stands for a projection and Fourier transform in the respective domain. 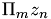 is the Fourier space amplitude adaption used on the initial values. Next
is the Fourier space amplitude adaption used on the initial values. Next 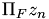 is nearly a complete GS step just without the last amplitude adaption. These interim results are weighted with the -factor and are substracted from the GS-result the way the above formula denotes. This finally yields the next iteration for
is nearly a complete GS step just without the last amplitude adaption. These interim results are weighted with the -factor and are substracted from the GS-result the way the above formula denotes. This finally yields the next iteration for 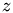 .
.
The bulk of the numerical work consists of the two Fourier transforms. Thus any attempt to parallelize the algorithm should start there. The CUFFT library provides already a CUDA based FFT implementation. The implementation of the projection operators can be perfectly parallelized as we will see later. A by-product of this project is a C++-Wrapper class for CUFFT for increasing the user friendliness of the API.
Shimobaba et al. [2] could calculate nearly 25 holograms per second on a GeForce 8800 GT, for comparison on a Core2DuoE6300 they could calculate 1.24 holograms per second. But as it turned out they did some things in an other way than this project, so their results are not comparable. They obtained their holograms by calculating the Fresnel diffraction integral, which can be written as a convolution. So they made use of CUFFT, which sped up the whole process.
Literature
- Design and characteristics of holographic neural photo-stimulation systems, S. Shoham et al. , Journal of Neural Engineering
- Phase retrieval algorithms: a comparison, J. R. Fienup
- Real-time digital holographic microscopy using the graphic processing unit, T. Shimobaba et al. , Optical Society of America
- Coherent X-Ray Optics, David M. Paganin, Oxford University Press
- CUFFT User Guide
- Relaxed Averaged Alternating Reflections for Diffraction Imaging, D.Russel Luke, arXiv:math/0405208v1
The commented program
#ifndef CUDA_KERNEL_STEP_16_CU_H #define CUDA_KERNEL_STEP_16_CU_H #include <vector> template<typename T> struct CUDAPrecisionTraits; template <> struct CUDAPrecisionTraits<cuComplex> { typedef float NumberType; typedef cuComplex CudaComplex; }; template <> struct CUDAPrecisionTraits<cuDoubleComplex> { typedef double NumberType; typedef cuDoubleComplex CudaComplex; }; template <> struct CUDAPrecisionTraits<float> { typedef float NumberType; typedef cuComplex CudaComplex; }; template <> struct CUDAPrecisionTraits<double> { typedef double NumberType; typedef cuDoubleComplex CudaComplex; };
enum: ParallelArch
Allows to choose the computing architecture.
enum ParallelArch { cpu, gpu_cuda, gpu_opencl };
Declaration of Kernel Wrapper Functions
void amplitude_adaption_r(cufftComplex *d_devPtr, const cufftComplex *d_original, int size, int height, int width, ParallelArch arch); #ifndef USE_SINGLE_PRECISION void amplitude_adaption_r(cufftDoubleComplex *d_devPtr, cufftDoubleComplex *d_original, int size, int height, int width, ParallelArch arch); #endif
void amplitude_adaption_f(cufftComplex *d_devPtr, int size, int sum, int height, int width, ParallelArch arch); #ifndef USE_SINGLE_PRECISION
void amplitude_adaption_f(cufftDoubleComplex *d_devPtr, int size,int sum, int height, int width, ParallelArch arch); #endif void amplitude_adaption_rRAAR(cufftComplex *d_devPtr, const cufftComplex *d_original, int size, int height, int width, ParallelArch arch); #ifndef USE_SINGLE_PRECISION void amplitude_adaption_rRAAR(cufftDoubleComplex *d_devPtr, cufftDoubleComplex *d_original, int size, int height, int width, ParallelArch arch); #endif void amplitude_adaption_fRAAR(cufftComplex *d_devPtr, int size, int height, int width, int sum,ParallelArch arch); #ifndef USE_SINGLE_PRECISION void amplitude_adaption_fRAAR(cufftDoubleComplex *d_devPtr, int size, int height, int width, int sum, ParallelArch arch); #endif void rescale(cufftComplex *d_devPtr, int size, int height, int width, ParallelArch arch); #ifndef USE_SINGLE_PRECISION void rescale(cufftDoubleComplex *d_devPtr, int size, int height, int width, ParallelArch arch); #endif void twilight_error(cufftComplex *d_devPtr, const cufftComplex *d_original, cufftComplex *d_error, int size, int height, int width, ParallelArch arch); #ifndef USE_SINGLE_PRECISION void twilight_error(cufftDoubleComplex *d_devPtr, cufftDoubleComplex *d_original, cufftDoubleComplex *d_error, int size, int height, int width, ParallelArch arch); #endif void randomize(cufftComplex *d_devPtr, const float *d_rndnumbers, int size, int height, int width, ParallelArch arch); #ifndef USE_SINGLE_PRECISION void randomize(cufftDoubleComplex *d_devPtr, const double *d_rndnumbers, int size, int height, int width, ParallelArch arch); #endif #endif // CUDA_KERNEL_STEP_16_CU_H
Header-files of CUDA utility-library
#include <cutil_inline.h>
Header for referencing CUDA based part
#include <cuda_kernel_wrapper_step-16.cu.h> #include <vector>
Device Functions
These functions are called in the kernels and run only on the GPU.
Function: __is_zero
template <typename T> __host__ __device__ bool __is_zero(T x); __host__ __device__ bool __is_zero(double x) { if(x >= 2e-16) {return true;}/ *true and false were switched, now it looks unlogical, but i think its better* / else return false; } __host__ __device__ bool __is_zero(float x) { if(x >= 2e-8) {return true;} else return false; }
Kernel Functions
These functions are the kernels and run only on the GPU.
Kernel: __amplitude_adaption_r
Kernel to calculate the amplitude adaption (projection) in realspace. To do this it suffices to consider the image as a linear array of pixels, as rescaling is a a local operation on the individual pixels.
- Parameters:
-
d_devPtr : Pointer to iterated image d_original : Pointer to original image for comparison size : size of image. Control variable for not accessing data outside range
template <typename T> __host__ __device__ void __amplitude_adaption_r_element(T *d_devPtr, const T *d_original, int x) {
This typedef returns the fitting number type to the FFT vector (float or double).
typedef typename CUDAPrecisionTraits<T>::NumberType NumberType;
Calculate the thread ID. The thread ID determines which pixel is calculated. int x = blockDim.x*blockIdx.x+threadIdx.x;
Copy pixel values from global memory to local memory, to avoid multiple reads of the same value.
NumberType real = d_devPtr[x].x;
NumberType imag = d_devPtr[x].y;
Calculate modulus of pixel (complex)value
NumberType abs = sqrt(real*real+imag*imag);
if original image is zero, then reconstructed image is zero, too
if(d_original[x].x==0) { d_devPtr[x].x=0; d_devPtr[x].y=0; } else {
rescaling of the complex values
if( __is_zero(abs))
{
real = (real/abs);
imag = (imag/abs);
}
write result back to global memory.
d_devPtr[x].x=real;
d_devPtr[x].y=imag;
}
}
Kernel: __amplitude_adaption_r
Kernel to calculate the amplitude adaption (projection) in realspace. To do this it suffices to consider the image as a linear array of pixels, as rescaling is a a local operation on the individual pixels.
- Parameters:
-
d_devPtr : Pointer to iterated image d_original : Pointer to original image for comparison size : size of image. Control variable for not accessing data outside range
template <typename T> __global__ void __amplitude_adaption_r(T *d_devPtr, const T *d_original, int size) {
Calculate the thread ID. The thread ID determines which pixel is calculated.
int x = blockDim.x*blockIdx.x+threadIdx.x;
Prevents kernel to calculate something outside the image vector.
if(x<size)
__amplitude_adaption_r_element(d_devPtr,d_original,x);
}
Wrapper Function: amplitude_adaption_r
Starts the templatized kernel.
- Parameters:
-
d_devPtr : Pointer to iterated image d_original : Pointer to original image for comparison size : Size of image. Control variable for not accessing data outside range height : height of image, is used to initialize number of blocks width : width of image, is used to initialize number of threads per block
template<typename T> void _amplitude_adaption_r(T *d_devPtr, const T *d_original, int size, int height,int width, ParallelArch arch) { switch(arch) { case gpu_cuda: // gpu
Calculates the number of blocks from the image size. There are 512 Threads per block to provide compatibility to older GPUs.
height = (size/512)+1;
__amplitude_adaption_r<T><<<height,512>>>(d_devPtr, d_original,size);
cudaThreadSynchronize();
break;
case cpu: //cpu
for(int i = 0;i < size;i++)
{__amplitude_adaption_r_element<T>(d_devPtr, d_original, i); }
break;
case gpu_opencl:
break;
}
}
Mere purpose of the following functions is to provide the necessary template specialization so that g++ can reference what nvcc has compiled. For parameter details look at _amplitude_adaption_r.
void amplitude_adaption_r(cufftComplex *d_devPtr, const cufftComplex *d_original, int size, int height, int width, ParallelArch arch) { _amplitude_adaption_r(d_devPtr, d_original, size, height, width, arch); } #ifndef USE_SINGLE_PRECISION void amplitude_adaption_r(cufftDoubleComplex *d_devPtr, const cufftDoubleComplex *d_original, int size, int height, int width, ParallelArch arch) { _amplitude_adaption_r(d_devPtr, d_original, size, height, width, arch); } #endif
Host+Device amplitude_adaption_f();
Kernel to calculate the amplitude adaption (projection) in Fourier space. This kernel is pretty similar to __amplitude_adaption_r thus we only comment on the differences.
- Parameters:
-
d_devPtr : Pointer to iterated image size : size of image. Control variable for not accessing data outside range sum : sum of illuminated pixel, needed to adapt the modulus in fourierspace
template <typename T> __host__ __device__ void __amplitude_adaption_f_element(T *d_devPtr, int size, int sum, int x) { typedef typename CUDAPrecisionTraits<T>::NumberType NumberType; NumberType real = d_devPtr[x].x; NumberType imag = d_devPtr[x].y; real/=size; imag/=size;
Calculate modulus of pixel (complex) value
NumberType abs = sqrt(real*real+imag*imag);
energy conservation scale factor
NumberType factor = sqrt(sum*1.0)/(size*1.0);
with conservation
if(__is_zero(abs)) { real = (real/abs)*factor; imag = (imag/abs)*factor; } else { real = 0; imag = 0; } d_devPtr[x].x=real; d_devPtr[x].y=imag; }
Kernel: __amplitude_adaption_f
Kernel to calculate the amplitude adaption (projection) in Fourier space. This kernel is pretty similar to __amplitude_adaption_r thus we only comment on on the differences.
- Parameters:
-
d_devPtr : Pointer to iterated image size : size of image. Control variable for not accessing data outside range sum : sum of illuminated pixel, needed to adapt the modulus in fourierspace
template <typename T> __global__ void __amplitude_adaption_f(T *d_devPtr, int size, int sum) { int x = blockDim.x*blockIdx.x+threadIdx.x; if(x<size) __amplitude_adaption_f_element(d_devPtr, size, sum, x); }
Wrapper Function: amplitude_adaption_f
Starts the templatized kernel.
- Parameters:
-
d_devPtr : Pointer to iterated image size : size of image. Control variable for not accessing data outside range sum : sum of illuminated pixel, needed to adapt the modulus in fourierspace height : height of image, is used to initialize number of blocks width : width of image, is used to initialize number of threads per block
template<typename T> void _amplitude_adaption_f(T *d_devPtr, int size, int sum,int height, int width, ParallelArch arch) { switch(arch) { case gpu_cuda: height = (size/512)+1; __amplitude_adaption_f<T><<<height,512>>>(d_devPtr, size, sum); cudaThreadSynchronize(); break; case cpu: //cpu for(int i = 0;i < size;i++) {__amplitude_adaption_f_element<T>(d_devPtr,size ,sum, i); } break; case gpu_opencl: break; } }
For parameter details look at _amplitude_adaption_f.
void amplitude_adaption_f(cufftComplex *d_devPtr,int sum, int size, int height, int width, ParallelArch arch) { _amplitude_adaption_f(d_devPtr,sum, size, height, width, arch); } #ifndef USE_SINGLE_PRECISION void amplitude_adaption_f(cufftDoubleComplex *d_devPtr,int sum, int size, int height, int width, ParallelArch arch) { _amplitude_adaption_f(d_devPtr, sum, size, height, width, arch); } #endif
Host+Device Function: __rescale_element
template <typename T> __host__ __device__ void __rescale_element(T *d_devPtr, int size, int x) {
rescaling of the complex values
d_devPtr[x].x/=size;
d_devPtr[x].y/=size;
}
Kernel: __rescale
Kernel to rescale last output of the FFT, this is normally done by amplitude_adaption_f, but since we don't want to adapt the modulus we have to use another function.
- Parameters:
-
d_devPtr : Pointer to iterated image size : Size of image. Control variable for not accessing data outside range
template<typename T> __global__ void __rescale(T *d_devPtr, int size) { int x = blockDim.x*blockIdx.x+threadIdx.x; if(x<size)
rescaling of the complex values
__rescale_element(d_devPtr, size, x); }
Wrapper Function: rescale
Starts the templatized kernel.
- Parameters:
-
d_devPtr : Pointer to iterated image size : Size of image. Control variable for not accessing data outside range height : height of image, is used to initialize number of blocks width : width of image, is used to initialize number of threads per block
template<typename T> void _rescale(T *d_devPtr, int size, int height, int width, ParallelArch arch) { switch(arch) { case gpu_cuda: height = (size/512)+1; __rescale<T><<<height, width>>>(d_devPtr,size); cudaThreadSynchronize(); break; case cpu: for(int i = 0;i < size;i++) __rescale_element(d_devPtr, size, i); break; case gpu_opencl: break; } }
For parameter details look at _rescale.
void rescale(cufftComplex *d_devPtr, int size, int height, int width, ParallelArch arch) { _rescale(d_devPtr, size, height, width, arch); } #ifndef USE_SINGLE_PRECISION template<typename T> void rescale(cufftDoubleComplex *d_devPtr, int size, int height, int width, ParallelArch arch) { _rescale(d_devPtr, size, height, width, arch); } #endif
Host __twilight_error_element
Kernel to calculate the deviation to the original image.
- Parameters:
-
d_devPtr : Pointer to iterated image d_original : Pointer to original image size : Size of image. Control variable for not accessing data outside range
template <typename T> __host__ __device__ void __twilight_error_element(T *d_devPtr, const T *d_original, T *d_error, int x) { typedef typename CUDAPrecisionTraits<T>::NumberType NumberType; d_error[x].x = 0; d_error[x].y = 0;
computed amplitude for current pixel
T a_ampl = d_devPtr[x];
NumberType abs_a = (a_ampl.x*a_ampl.x + a_ampl.y*a_ampl.y);
original amplitude for current pixel
T A_ampl = d_original[x];
NumberType abs_A = (A_ampl.x*A_ampl.x + A_ampl.y*A_ampl.y);
error margins
NumberType t_light = 0.1;
NumberType t_dark = 3.333e-4;
errors
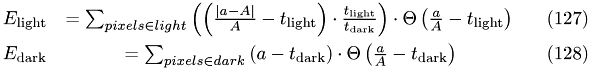
with 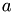 the current iterated intensity and
the current iterated intensity and 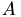 the intensity in the original image. The total error is the sum of
the intensity in the original image. The total error is the sum of 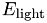 and
and 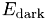 .
.
NumberType err_light = (abs(abs_A-abs_a)/abs_A - t_light);
NumberType err_dark = (abs_a-t_dark);
if(A_ampl.x == 0)
{//error for dark pixel
if(err_dark>0)
{
d_error[x].x = err_dark;
}
}
else
{//error for light pixel
if(err_light>0)
{
d_error[x].x= err_light*(t_dark/t_light);
}
}
}
Kernel: __twilight_error
Kernel to calculate the deviation to the original image.
- Parameters:
-
d_devPtr : Pointer to iterated image d_original : Pointer to original image size : Size of image. Control variable for not accessing data outside range
template <typename T> __global__ void __twilight_error(T *d_devPtr, const T *d_original, T *d_error, int size) { int x = blockDim.x*blockIdx.x+threadIdx.x; if(x<size) __twilight_error_element(d_devPtr, d_original, d_error, x); }
Wrapper Function: _twilight_error
Starts the templatized kernel.
- Parameters:
-
d_devPtr : Pointer to iterated image size : Size of image. Control variable for not accessing data outside range sum : sum of illuminated pixel, needed to adapt the modulus in fourierspace
template <typename T> void _twilight_error(T *d_devPtr,const T *d_original,T *d_error, int size, int height, int width, ParallelArch arch ) { switch(arch) { case gpu_cuda: height = (size/512)+1; __twilight_error<T><<<height, width>>>(d_devPtr, d_original, d_error, size); cudaThreadSynchronize(); break; case cpu: //cpu for(int i = 0;i < size;i++) {__twilight_error_element<T>(d_devPtr, d_original, d_error, i); } break; case gpu_opencl: break; } }
Wrapper Function: twilight_error
For Parameter details look at _twilight_error.
void twilight_error(cufftComplex *d_devPtr, const cufftComplex *d_original, cufftComplex *d_error, int size, int height, int width, ParallelArch arch) { _twilight_error(d_devPtr, d_original,d_error, size, height, width,arch); } #ifndef USE_SINGLE_PRECISION void twilight_error(cufftDoubleComplex *d_devPtr, const cufftDoubleComplex *d_original, cufftDoubleComplex *d_error, int size, int height, int width, ParallelArch arch) { _twilight_error(d_devPtr, d_original, d_error, size, height, width, arch); } #endif
Host __randomize_element
template <typename T> __host__ __device__ void __randomize_element( typename CUDAPrecisionTraits<T>::CudaComplex *d_devPtr, const T *d_rndnumbers, int x) { typedef typename CUDAPrecisionTraits<T>::NumberType NumberType; NumberType rnd = d_rndnumbers[x]*6.28318; NumberType real = cos(rnd); NumberType imag = sin(rnd);
set all pixels to random values
d_devPtr[x].x=real;
d_devPtr[x].y=imag;
}
Kernel: __randomize
Kernel to set initial random configuration of d_image.
- Parameters:
-
d_devPtr : Pointer to iterated image d_rndnumbers : Pointer to array with random numbers d_devPtr : Pointer to iterated image size : Size of image. Control variable for not accessing data outside range
template <typename T> __global__ void __randomize( typename CUDAPrecisionTraits<T>::CudaComplex *d_devPtr, const T *d_rndnumbers, int size) { int x = blockDim.x*blockIdx.x+threadIdx.x; if(x<size) __randomize_element(d_devPtr, d_rndnumbers, x); }
Wrapper Function: randomize
Starts the templatized kernel. Kernel to set initial random configuration of d_image.
- Parameters:
-
d_devPtr : Pointer to iterated image d_rndnumbers : Pointer to array with random numbers size : Size of image. Control variable for not accessing data outside range height : height of image, is used to initialize number of blocks width : width of image, is used to initialize number of threads per block
template <typename T> void _randomize(typename CUDAPrecisionTraits<T>::CudaComplex *d_devPtr,const T *d_rndnumbers, int size, int height, int width, ParallelArch arch) { switch(arch) { case gpu_cuda: height = (size/512)+1; __randomize<T><<<height, width>>>(d_devPtr, d_rndnumbers, size); cudaThreadSynchronize(); break; case cpu: //cpu for(int i = 0;i < size;i++) {__randomize_element<T>(d_devPtr, d_rndnumbers, i); } break; case gpu_opencl: break; } }
For parameter details look at _randomize.
void randomize(cufftComplex *d_devPtr,const float *d_rndnumbers, int size, int height, int width, ParallelArch arch) { _randomize(d_devPtr, d_rndnumbers, size, height, width, arch); } #ifndef USE_SINGLE_PRECISION void randomize(cufftDoubleComplex *d_devPtr,const double *d_rndnumbers, int size, int height, int width, ParallelArch arch) { _randomize(d_devPtr, d_rndnumbers, size, height, width, arch); } #endif
Host+Device __amplitude_adaption_rRAAR_element
Kernel to calculate the amplitude adaption (projection) in realspace.
- Parameters:
-
d_devPtr : Pointer to iterated image d_original : Pointer to original image for comparison size : Size of image. Control variable for not accessing data outside range
template <typename T> __host__ __device__ void __amplitude_adaption_rRAAR_element(T *d_devPtr, const T *d_original, int x) { typedef typename CUDAPrecisionTraits<T>::NumberType NumberType; NumberType real = d_devPtr[x].x; NumberType imag = d_devPtr[x].y;
Calculate modulus of pixel (complex) value
NumberType abs = sqrt(real*real+imag*imag);
Prevents kernel to calculate something outside the image vector.
if original image is zero, then reconstructed image is zero too
if(d_original[x].x==0) { d_devPtr[x].x=0; d_devPtr[x].y=0; } else {
rescaling of the complex values
if( __is_zero(abs) )
{
real = (real/abs);
imag = (imag/abs);
}
d_devPtr[x].x=real;
d_devPtr[x].y=imag;
}
}
Kernel: __amplitude_adaption_rRAAR
Kernel to calculate the amplitude adaption (projection) in realspace.
- Parameters:
-
d_devPtr : Pointer to iterated image d_original : Pointer to original image for comparison size : Size of image. Control variable for not accessing data outside range
template <typename T> __global__ void __amplitude_adaption_rRAAR(T *d_devPtr, const T *d_original, int size) { typedef typename CUDAPrecisionTraits<T>::NumberType NumberType; int x = blockDim.x*blockIdx.x+threadIdx.x;
Prevents kernel to calculate something outside the image vector.
if(x<size)
__amplitude_adaption_rRAAR_element(d_devPtr, d_original, x);
}
Wrapper Function: _amplitude_adaption_rRAAR
Kernel to calculate the amplitude adaption (projection) in realspace.
- Parameters:
-
d_devPtr : Pointer to iterated image d_original : Pointer to original image for comparison size : size of image control variable for not accessing data outside range height : height of image, is used to initialize number of blocks width : width of image, is used to initialize number of threads per block
template <typename T> void _amplitude_adaption_rRAAR(T *d_devPtr, const T *d_original, int size, int height,int width, ParallelArch arch) { switch(arch) { case gpu_cuda: height = (size/512)+1; __amplitude_adaption_rRAAR<T><<<height,width>>>(d_devPtr, d_original,size); cudaThreadSynchronize(); break; case cpu: //cpu for(int i = 0;i < size;i++) {__amplitude_adaption_rRAAR_element<T>(d_devPtr, d_original, i); } break; case gpu_opencl: break; } }
For parameter details look at _amplitude_adaption_rRAAR.
void amplitude_adaption_rRAAR(cufftComplex *d_devPtr, const cufftComplex *d_original, int size, int height, int width, ParallelArch arch) { _amplitude_adaption_rRAAR(d_devPtr,d_original,size, height, width,arch); } #ifndef USE_SINGLE_PRECISION void amplitude_adaption_rRAAR(cufftDoubleComplex *d_devPtr, const cufftDoubleComplex *d_original, int size, int height, int width, ParallelArch arch) { _amplitude_adaption_rRAAR(d_devPtr,d_original,size, height, width,arch); } #endif
Host amplitude_adaption_fRAAR_element
Kernel to calculate the amplitude adaption(projection) in realspace.
- Parameters:
-
d_devPtr : Pointer to iterated image size : Size of image. Control variable for not accessing data outside range sum : sum of illuminated pixel, needed to adapt the modulus in Fourier space
template <typename T> __host__ __device__ void __amplitude_adaption_fRAAR_element(T *d_devPtr, int size,int sum, int x) { typedef typename CUDAPrecisionTraits<T>::NumberType NumberType; NumberType real = d_devPtr[x].x; NumberType imag = d_devPtr[x].y;
normalisation of the fft picture
real/=size;
imag/=size;
Calculate modulus of pixel (complex) value
NumberType abs = sqrt(real*real+imag*imag);
energy conservation scale factor
NumberType factor = sqrt(sum*1.0)/(size*1.0);
with conservation
if( __is_zero(abs) ) { real = (real/abs)*factor; imag = (imag/abs)*factor; } else { real = 0; imag = 0; } d_devPtr[x].x=real; d_devPtr[x].y=imag; }
Kernel: __amplitude_adaption_fRAAR
Kernel to calculate the amplitude adaption(projection) in realspace.
- Parameters:
-
d_devPtr : Pointer to iterated image size : Size of image. Control variable for not accessing data outside range sum : sum of illuminated pixel, needed to adapt the modulus in Fourier space
template <typename T> __global__ void __amplitude_adaption_fRAAR(T *d_devPtr, int size,int sum) { int x = blockDim.x*blockIdx.x+threadIdx.x; if(x<size) __amplitude_adaption_fRAAR_element(d_devPtr, size, sum,x); }
Wrapper Function: amplitude_adaption_fRAAR
Kernel to calculate the amplitude adaption (projection) in Fourier space.
- Parameters:
-
d_devPtr : Pointer to iterated image size : Size of image. Control variable for not accessing data outside range sum : sum of illuminated pixel, needed to adapt the modulus in fourierspace height : height of image, is used to initialize number of blocks width : width of image, is used to initialize number of threads per block
template<typename T> void _amplitude_adaption_fRAAR(T *d_devPtr, int size, int sum,int height, int width, ParallelArch arch) { switch(arch) { case gpu_cuda: height = (size/512)+1; __amplitude_adaption_fRAAR<T><<<height, width>>>(d_devPtr,size,sum); cudaThreadSynchronize(); break; case cpu: for(int i = 0;i < size;i++) {__amplitude_adaption_fRAAR_element<T>(d_devPtr,size ,sum ,i); } break; case gpu_opencl: break; } }
For parameter details look at _amplitude_adaption_fRAAR.
void amplitude_adaption_fRAAR(cufftComplex *d_devPtr,int size, int sum, int height, int width, ParallelArch arch) { _amplitude_adaption_fRAAR(d_devPtr,size, sum, height, width, arch); } #ifndef USE_SINGLE_PRECISION void amplitude_adaption_fRAAR(cufftDoubleComplex *d_devPtr,int size, int sum, int height, int width, ParallelArch arch) { _amplitude_adaption_fRAAR(d_devPtr,size, sum, height, width, arch); } #endif
File : cuda_driver_ step_16 "step-16".h
#ifndef CUDADriver_STEP_16_H #define CUDADriver_STEP_16_H #include <lac/blas++.h> #include <vector> #include <string> #include <sstream>
deal.II
#include <base/parameter_handler.h> using namespace std;
Each programm has its own namespace, so it is possible to combine the different driver classes in more complex projects.
namespace step16 { template<typename T> struct VTraits { typedef typename PrecisionTraits<T>::NumberType NumberType; typedef typename PrecisionTraits<T>::CudaComplex CudaComplex; typedef typename blas_pp<CudaComplex, cublas>::Vector FFTVector; typedef std::vector<CudaComplex> ImageVector; }; class Parameters { public: static void declare(::ParameterHandler & prm); void get(::ParameterHandler & prm);
Parameters(stringstream &filename, stringstream &outputfolder, int iterations);
Parameters(){}
stringstream filename;
stringstream outputfolder;
stringstream append;
int iterations;
int algorithm;
int realisations;
private:
Parameters(const Parameters & ) {}
Parameters & operator = (const Parameters & / *other* /)
{
return *this;
}
};
class: Image
This class encapsules the image and image properties, for easy access in the simulation (CUDAPhaseHologramDriver-class)
template<typename T> class Image : public VTraits<T>::ImageVector { public: typedef typename VTraits<T>::ImageVector Base; typedef typename VTraits<T>::FFTVector FFTVector; typedef typename VTraits<T>::CudaComplex CudaComplex; typedef typename FFTVector::blas_wrapper_type BW;
standard constructor
Image() {}
Image(QImage img);
width of image
int width;
height of image
int height;
sum over all white pixels, needed for energy conservation (same illumination energy in real and fourierspace)
int sum;
copy operator for data transfer back to host
Image & operator = (const FFTVector& / *src* /); Image & operator = (const Image<T>& other) { width = other.width; height = other.height; sum = other.sum;
reference to base object
Base & self = *this; self = other; return *this; }
copy ctor
Image(const Image<T>& other) { *this = other; } private: };
class: CUDAPhaseHologramDriver
This class transfers the input image to the GPU and runs the algorithm in a the member function compute(). The results are copied back to the host. The class holds the image properties and the working copy of the image as attributes.
template <typename T> class CUDAPhaseHologramDriver { public: typedef typename VTraits<T>::NumberType NumberType; typedef typename VTraits<T>::FFTVector FFTVector; typedef typename VTraits<T>::CudaComplex CudaComplex; typedef typename FFTVector::blas_wrapper_type BW; CUDAPhaseHologramDriver(int iterations, Image<T> &image, Image<T> &ftimage, std::vector<double> &error, std::vector<Image<T> > &iterationsteps); ~CUDAPhaseHologramDriver (); void compute(); void computeRAAR(); void computeRAAR2(); const FFTVector & get_d_image() const ; private: int iterations; Image<T> * image; Image<T> * ftimage; FFTVector d_image; FFTVector d_original; int size; int width; int height; int sum; std::vector<double> &errorout; std::vector<Image<T> > &iterationsteps; }; template<cufftType_t cufft_type> struct FFTTraits; template<> struct FFTTraits<CUFFT_C2C> { typedef cuComplex T_dst; typedef cuComplex T_src; static cufftResult exec(cufftHandle &plan, cufftComplex *dst, cufftComplex *src, int direction) { return cufftExecC2C(plan, src, dst, direction); } }; template<> struct FFTTraits<CUFFT_R2C> { typedef float T_dst; typedef cuComplex T_src; static cufftResult exec(cufftHandle &plan, cufftComplex *dst, cufftReal *src, int / *direction* /) { return cufftExecR2C(plan, src, dst); } }; template<> struct FFTTraits<CUFFT_C2R> { typedef float T_dst; typedef cuComplex T_src; static cufftResult exec(cufftHandle &plan, cufftReal *dst, cufftComplex *src, int / *direction* /) { return cufftExecC2R(plan, src, dst); } }; template<> struct FFTTraits<CUFFT_Z2Z> { typedef cuDoubleComplex T_dst; typedef cuDoubleComplex T_src; static cufftResult exec(cufftHandle &plan, cufftDoubleComplex *dst, cufftDoubleComplex *src, int direction) { return cufftExecZ2Z(plan, src, dst, direction); } }; template<> struct FFTTraits<CUFFT_D2Z> { typedef cuDoubleComplex T_dst; typedef double T_src; static cufftResult exec(cufftHandle &plan, cufftDoubleComplex *dst, cufftDoubleReal *src, int / *direction* /) { return cufftExecD2Z(plan, src, dst); } }; template<> struct FFTTraits<CUFFT_Z2D> { typedef double T_dst; typedef cuDoubleComplex T_src; static cufftResult exec(cufftHandle &plan, cufftDoubleReal *dst, cufftDoubleComplex *src, int / *direction* /) { return cufftExecZ2D(plan, src, dst); } }; template <int d, cufftType_t cufft_type, bool inv> class CUDAFFT { public: static const int dim = d; static const cufftType_t variant = cufft_type; static const bool inverse = inv; typedef typename FFTTraits<cufft_type>::T_dst T_dst; typedef typename FFTTraits<cufft_type>::T_src T_src; typedef typename VTraits<T_dst>::FFTVector FFTVectorDST; typedef typename VTraits<T_src>::FFTVector FFTVectorSRC; CUDAFFT(); ~CUDAFFT(); void operator() (FFTVectorDST *dst, FFTVectorSRC *src, int width, int height);
create cufft handle object
cufftHandle plan; private: }; template <typename T> class CUDArnd { public: typedef typename VTraits<T>::NumberType NumberType; typedef typename VTraits<T>::FFTVector FFTVector; private: }; } // namespace step16 END #endif // CUDADriver_STEP_16_H
File : cuda_driver_ step_16 "step-16".hh
#ifndef CUDA_DRIVER_STEP_16_HH #define CUDA_DRIVER_STEP_16_HH #include "cuda_driver_step-16.h"
Declarition of kernel-wrapper-functions
#include "cuda_kernel_wrapper_step-16.cu.h" #include <cutil_inline.h>
Funktion: declare
Diese Funktion bringt dem Parameterhandler bei, welche Parameter erwartet werden.
void step16::Parameters::declare(::ParameterHandler & prm)
{
Die ParameterHandler-Klasse erlaubt es, die Parameter-Datei in Abschnitte zu unterteilen und fuer Parameter mit numerischen Werten Bereichsschranken anzugeben. Wenn man zu seiner Umwelt nett sein moechte, dann gibt man sich mit der Wahl der Parameternamen und ihrer Dokumentation (letztes Argument von declare_entry()) etwas Muehe.
prm.enter_subsection("Dimensions of test problems."); prm.declare_entry ("iterations", "20", ::Patterns::Integer(), "Number of iterations"); prm.declare_entry ("input file", "pattern.bmp", ::Patterns::Anything(), "Name of bmp input file"); prm.declare_entry ("output folder", "./results/", ::Patterns::Anything(), "Ouputfolder for results, form ./foldername/"); prm.declare_entry("algorithm", "1", ::Patterns::Integer(), "Choose algorithm:\n" "1: Gerchberg Saxton\n" "2: RAAR"); prm.declare_entry("apendix", "", ::Patterns::Anything(), "append something to your output file names"); prm.declare_entry ("realisations", "20", ::Patterns::Integer(), "Number of realisations"); prm.leave_subsection(); }
Funktion: get
Diese Funktion liest die Parameter in das Objekt.
void step16::Parameters::get(::ParameterHandler & prm) { prm.enter_subsection("Dimensions of test problems."); iterations = prm.get_integer ("iterations") ; filename.str(prm.get ("input file")) ; outputfolder.str(prm.get("output folder")); algorithm = prm.get_integer("algorithm"); append.str(prm.get("apendix")); realisations = prm.get_integer ("realisations") ; prm.leave_subsection(); }
Constructor: Image
The constructor loads an black white image out of a file and stores it to an array. It also sets the attributes sum, height and width.
- Parameters:
-
img : QImage input file
template<typename T> step16::Image<T>::Image(QImage img) : Base(), width(img.width()), height(img.height()), sum(0) { this->resize( width*height);
Loop over all pixels.
for(int i=0;i< height;i++) { for(int j=0;j< width;j++) { QColor c = QColor::fromRgb (img.pixel(j,i) ); if (c == Qt::white) { (*this)[i*height+j].x = 1.0; //realpart (*this)[i*height+j].y = 0.0; //imag part sum++;
std::cout<<i<<" "<<j<<" "<<std::endl;
}
else if (c == Qt::black)
{
(*this)[i*height+j].x = 0.0;
(*this)[i*height+j].y = 0.0;
}
}
}
Write out of image properties.
std::cout
<<"host: width:"<<(*this).width
<<" height:"<<(*this).height
<<" size:"<<(*this).size()<< std::endl;
}
Operator = FFTVector
Copies data from device to host.
template<typename T> step16::Image<T> & step16::Image<T>::operator = (const / *step16::* /FFTVector& src) { if (this->size() != src.size()) this->resize(src.size()); CudaComplex * dst_ptr = &(*this)[0]; const CudaComplex * src_ptr = src.array().val(); #ifdef DEBUG std::cout << "src n_pixels : " << src.size() << " dst n_pixels : " << this->size() << std::endl; #endif BW::GetVector(this->size(), src_ptr, 1, dst_ptr, 1); return *this; }
Constructor: CUDAPhaseHologramDriver
The constructor of the CUDAPhaseHologramDriver class alocates memory on the GPU and transfers the image data.
- Parameters:
-
image : vector on host with image data, stores also last iteration of realspace amplitudes and phases ftimage : this vector holds last iteration of fourier space amplitudes and phases
template <typename T> step16::CUDAPhaseHologramDriver<T>:: CUDAPhaseHologramDriver(int _iterations, Image<T> &_image, Image<T> &_ftimage, std::vector<double> &_error, std::vector<Image<T> > &_iterationsteps) : iterations(_iterations), image(&_image), ftimage(&_ftimage), size(_image.size()), width(_image.width), height(_image.height), sum(_image.sum), errorout(_error), iterationsteps(_iterationsteps) {
initialize vectors
errorout.resize(iterations);
iterationsteps.resize(iterations);
BW::Init();
cudaThreadSynchronize();
initilize and transfer working copy of image to device
d_image.reinit(_image.size() );
d_image = _image;
copy of original image on device
d_original.reinit(_image.size() );
d_original = d_image;
std::cout<<"device: width:"<<width<<" height:"<<height
<<" size:"<<size<< std::endl;
}
Destructor: CUDAPhaseHologramDriver
The destructor frees memory ant GPU and sets host-data pointers to NULL.
template<typename T> step16::CUDAPhaseHologramDriver<T>::~CUDAPhaseHologramDriver() { BW::Shutdown(); image = NULL; ftimage = NULL; }
Funktion: run
This function calls the FFT and kernels, which are necessary for the algorithm.
template<typename T> void step16::CUDAPhaseHologramDriver<T>::compute() {
Pseudo template to choose the device for calculation.
ParallelArch arch = gpu_cuda;
CUDAFFT<2,CUFFT_C2C,false> FFT_forward;
create cufft handle object
cufftHandle plan;
creates 2D FFT plan
cufftPlan2d(&plan, width ,height ,CUFFT_C2C);
Algorithm Gerchberg-Saxton
for(int i=0;i<iterations;i++) { //FFT_forward(d_image.array().val(),d_image.array().val(),width,height); cufftExecC2C(plan, d_image.array().val(), d_image.array().val(), CUFFT_FORWARD); cudaThreadSynchronize();
std::cout<<"d_image nach ffft " << i<<"\t"<<d_image.l2_norm().x<<std::endl;
amplitude_adaption_f(d_image.array().val(), size, sum,
height,width, arch);
cudaThreadSynchronize();
std::cout<<"d_image nach anpassung f " << i<<"\t"<<d_image.l2_norm().x<<std::endl;
cufftExecC2C(plan, d_image.array().val(), d_image.array().val(),
CUFFT_INVERSE);
cudaThreadSynchronize();
calculate the root square mean error(RSME)
/ *cuComplex zero;
zero.x = 0.;
zero.y = 0.;
FFTVector error(d_image.size());
error *= zero;
error = d_image;
std::cout<<"d_image " << i<<"\t"<<error.l2_norm().x;
error = d_original;
std::cout<<" d_original " << i<<"\t"<<error.l2_norm().x;
error = d_image;
error -= d_original;
std::cout<<" Error " << i<<"\t"<<error.l2_norm().x<<std::endl;
errorout[i]=error.l2_norm().x; * /
other error calculation
FFTVector d_error(size);
twilight_error(d_image.array().val(),
d_original.array().val(),
d_error.array().val(),
size,height,width,arch);
cudaThreadSynchronize();
errorout[i] = d_error.sum();
output current iteration result
iterationsteps[i] = d_image;
amplitude_adaption_r(d_image.array().val(),d_original.array().val(),size,
height,width,arch);
cudaThreadSynchronize();
std::cout<<"d_image nach anpassun r " << i<<"\t"<<d_image.l2_norm().x<<std::endl;
}
cufftExecC2C(plan, d_image.array().val(), d_image.array().val(),
CUFFT_FORWARD);
cudaThreadSynchronize();
output last image of iteration in fourierspace
FFTVector d_copy;
d_copy = d_image;
rescale(d_copy.array().val(),size,height,width, arch);
cudaThreadSynchronize();
(*ftimage) = d_copy;
initilize attributes of ftimage
(*ftimage).width = width;
(*ftimage).height = height;
amplitude_adaption_f(d_image.array().val(),size,sum,height,width, arch);
cudaThreadSynchronize();
cufftExecC2C(plan, d_image.array().val(),d_image.array().val(),
CUFFT_INVERSE);
cudaThreadSynchronize();
copy result back to host and clean up
(*image) = d_image;
cufftDestroy(plan);
}
template<typename T> void step16::CUDAPhaseHologramDriver<T>::computeRAAR()
{
ParallelArch arch = gpu_cuda;
copy of image
FFTVector d_copy;
create cufft handle object
cufftHandle plan;
creates 2D FFT plan
cufftPlan2d(&plan, width ,height ,CUFFT_C2C);
Algorithm RAAR
for(int i=0;i<iterations;i++) { cout<<"iteration:"<<i<<endl;
save copy of current iteration
d_copy = d_image;
temporary copies for RAAR-algorithm
FFTVector tmp;
FFTVector tmp2;
calculate the beta for current step: 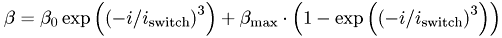
float beta_0 = 0.75; float beta_max = 0.99; float beta = 0; int i_switch = 3.0; float factor = exp(pow(-i*1.0/i_switch,3.0)); beta = beta_0*factor + beta_max*(1 - factor); cout<<"beta:"<<beta<<endl; cufftExecC2C(plan, d_image.array().val(), d_image.array().val(), CUFFT_FORWARD); cudaThreadSynchronize();
std::cout<<"d_image nach ffft " << i<<"\t"<<d_image.l2_norm().x<<std::endl;
amplitude_adaption_f(d_image.array().val(),size,sum,height,
width, arch);
cudaThreadSynchronize();
std::cout<<"d_image nach anpassung f " << i<<"\t"<<d_image.l2_norm().x<<std::endl;
cufftExecC2C(plan, d_image.array().val(), d_image.array().val(),
CUFFT_INVERSE);
cudaThreadSynchronize();
calculate the root square mean error(RSME)
/ *cuComplex zero;
zero.x = 0.;
zero.y = 0.;
FFTVector error(d_image.size());
error *= zero;
error = d_image;
std::cout<<"d_image " << i<<"\t"<<error.l2_norm().x;
error = d_original;
std::cout<<" d_original " << i<<"\t"<<error.l2_norm().x;
error = d_image;
error -= d_original;
std::cout<<" Error " << i<<"\t"<<error.l2_norm().x<<std::endl;
errorout[i]=error.l2_norm().x; * /
other error calculation
FFTVector d_error(size);
twilight_error(d_image.array().val(),d_original.array().val(),d_error.array().val(),
size,height,width, arch);
cudaThreadSynchronize();
errorout[i] = d_error.sum();
output current iteration result
iterationsteps[i] = d_image;
tmp2 = d_image;
amplitude_adaption_r(d_image.array().val(),d_original.array().val(),size,
height,width,arch);
cudaThreadSynchronize();
std::cout<<"d_image nach anpassun r " << i<<"\t"<<d_image.l2_norm().x<<std::endl;
RAAR
cuComplex factor2;
factor2.x = 2.0;
factor2.y = 0.0;
d_image*=factor2;
tmp = d_copy;
amplitude_adaption_r(tmp.array().val(),d_original.array().val(),size,height,
width,arch);
amplitude_adaption_f(d_copy.array().val(),size,sum,height,width);
d_image-=tmp;
d_image-=tmp2;
d_image+= d_copy;
factor2.x = beta;
d_image *= factor2;
factor2.x=0.5*(1.0-beta);
tmp2 *= factor2;
d_image+=tmp2;
}
cufftExecC2C(plan, d_image.array().val(), d_image.array().val(),
CUFFT_FORWARD);
cudaThreadSynchronize();
output last image of iteration in fourierspace
d_copy = d_image;
rescale(d_copy.array().val(),size,height,width,arch);
cudaThreadSynchronize();
(*ftimage) = d_copy;
initilize attributes of ftimage
(*ftimage).width = width;
(*ftimage).height = height;
amplitude_adaption_f(d_image.array().val(),size,sum,height,width,arch);
cudaThreadSynchronize();
cufftExecC2C(plan, d_image.array().val(),d_image.array().val(),
CUFFT_INVERSE);
cudaThreadSynchronize();
copy result back to host and clean up
(*image) = d_image;
cufftDestroy(plan);
}
template<typename T> void step16::CUDAPhaseHologramDriver<T>::computeRAAR2()
{
ParallelArch arch = gpu_cuda;
initilize with random numbers
typename blas_pp<NumberType, cublas>::Vector d_rnd(size);
curandGenerator_t gen; curandCreateGenerator(&gen,CURAND_RNG_PSEUDO_DEFAULT); curandSetPseudoRandomGeneratorSeed(gen,1234ULL); curandGenerateUniform(gen,d_rnd.array().val(),size); randomize(d_image.array().val(),d_rnd.array().val(),size,height,width);
copy of image
FFTVector d_copy;
create cufft handle object
cufftHandle plan;
creates 2D FFT plan
cufftPlan2d(&plan, width ,height ,CUFFT_C2C);
Algorithm RAAR
for(int i=0;i<iterations;i++) { //cout<<"iteration:"<<i<<endl;
save copy of current iteration
d_copy = d_image;
temporary copies for RAAR-algorithm
FFTVector tmp;
FFTVector tmp2;
calculate the beta for current step:
float beta_0 = 0.75; float beta_max = 0.99; float beta = 0; int i_switch = 3.0; float factor = exp(pow(-i*1.0/i_switch,3.0)); beta = beta_0*factor + beta_max*(1 - factor);
cout<<"beta:"<<beta<<endl;
cufftExecC2C(plan, d_image.array().val(), d_image.array().val(),
CUFFT_FORWARD);
cudaThreadSynchronize();
other error calculation
FFTVector d_error(size);
twilighterror(d_image.array().val(),d_original.array().val(),d_error.array().val(),
errorout,size,height,width,i);
cudaThreadSynchronize();
errorout[i] = d_error.sum();
output current iteration result
iterationsteps[i] = d_image;
amplitude_adaption_r(d_image.array().val(),d_original.array().val(),size,
height,width);
cudaThreadSynchronize();
cufftExecC2C(plan, d_image.array().val(), d_image.array().val(),
CUFFT_INVERSE);
cudaThreadSynchronize();
tmp2 = d_image;
amplitude_adaption_f(d_image.array().val(),size,sum,height,width);
cudaThreadSynchronize();
std::cout<<"d_image nach anpassun r " << i<<"\t"<<d_image.l2_norm().x<<std::endl;
RAAR
cuComplex factor2;
factor2.x = 2.0;
factor2.y = 0.0;
d_image*=factor2;
tmp = d_copy;
amplitude_adaption_f(tmp.array().val(), size, sum, height,width);
amplitude_adaption_f(d_copy.array().val(),size,sum,height,width);
d_image-=tmp;
d_image-=tmp2;
d_image+= d_copy;
factor2.x = beta;
d_image *= factor2;
factor2.x=0.5*(1.0-beta);
tmp2 *= factor2;
d_image+=tmp2;
}
output last image of iteration on SLM
(*ftimage) = d_image;
initilize attributes of ftimage
(*ftimage).width = width;
(*ftimage).height = height;
cufftExecC2C(plan, d_image.array().val(), d_image.array().val(),
CUFFT_FORWARD);
cudaThreadSynchronize();
rescale(d_image.array().val(),size,height,width, arch);
cudaThreadSynchronize();
copy result back to host and clean up
(*image) = d_image;
cufftDestroy(plan);
curandDestroyGenerator(gen);
}
Function: get_d_image
Function returns reference to d_image, so it can be used by functions outside the PhaseHologramDriver.
template <typename T> const typename step16::CUDAPhaseHologramDriver<T>::FFTVector & step16::CUDAPhaseHologramDriver<T>::get_d_image() const { return this->d_image; }
Constructor: CUDAfft
template<int dim, cufftType_t cufft_type, bool inverse> step16::CUDAFFT< dim, cufft_type,inverse>::CUDAFFT() {}
Destructor: CUDAfft
template < int dim, cufftType_t cufft_type, bool inverse> step16::CUDAFFT<dim, cufft_type, inverse>::~CUDAFFT() { cufftDestroy(plan); }
Operator: ()
template <int dim, cufftType_t cufft_type, bool inverse> void step16::CUDAFFT<dim, cufft_type, inverse>::operator() (FFTVectorDST * dst, FFTVectorSRC * src, int width, int height) {
create different plans
switch(dim) { case 1: cufftPlan1d(&plan, width , cufft_type,1); case 2: cufftPlan2d(&plan, width ,height ,cufft_type); break; case 3:
cufftPlan3d(&plan, width ,depth, height , CUFFT_);
default: break; } cufftResult result = FFTTraits<cufft_type>::exec(plan, dst.array().val(), src.array().val(), (inverse ? CUFFT_INVERSE : CUFFT_FORWARD) ); cudaThreadSynchronize(); if(result!=CUFFT_SUCCESS) { switch(result) { case CUFFT_INVALID_PLAN: std::cout<<"CUFFT is passed an invalid plan handle."<<std::endl; case CUFFT_ALLOC_FAILED: std::cout<<"CUFFT failed to allocate GPU memory."<<std::endl; case CUFFT_INVALID_TYPE: std::cout<<"The user requests an unsupported type."<<std::endl; case CUFFT_INVALID_VALUE: std::cout<<"The user specifies a bad memory pointer."<<std::endl; case CUFFT_INTERNAL_ERROR: std::cout<<"Internal driver errors."<<std::endl; case CUFFT_EXEC_FAILED: std::cout<<"CUFFT failed to execute an FFT on the GPU."<<std::endl; case CUFFT_SETUP_FAILED: std::cout<<"The CUFFT library failed to initialize."<<std::endl; case CUFFT_INVALID_SIZE: std::cout<<"The user specifies an unsupported FFT size."<<std::endl; case CUFFT_UNALIGNED_DATA: std::cout<<"Input or output does not satisfy texture alignment requirements."<<std::endl; } } } #endif // CUDA_DRIVER_STEP_16_HH #include "step-16.hh" using namespace std;
Funktion: main
The main function reads a file name from prompt and invokes with it the simulation control class.
int main(int / *argc* /, char *argv[]) { using namespace step16;
Deklariere Parameter und lese aus einer Datei, die genauso heisst wie das Programm erweitert um die Endung ".prm". Die gelesenen Parameter werden in eine log-Datei geschrieben.
::ParameterHandler prm_handler;
Parameters::declare(prm_handler);
std::string prm_filename(argv[0]);
prm_filename += "-hologram.prm";
prm_handler.read_input (prm_filename);
Parameters param;
param.get(prm_handler);
/ *prm_filename += ".log";
std::ofstream log_out_text(prm_filename.c_str());
prm_handler.print_parameters (log_out_text,
::ParameterHandler::Text);* /
MyFancySimulation<float> machma(param);
machma.run();
machma.output();
}
Results
The main results of this project are:
- phase holograms can be computated much faster on the GPU than on the CPU
- hologram generation can be completed roughliy within time limits prescribed by the experiment
- a modular test bench for hologram generating algorithms
Here the results in detail. 150 iteration steps including host device data transfer on 512x512 pixel image need approximately 1.2 seconds. The data transfer itself from host to GPU and back needs 0.6 seconds, so the actual calculating time is 0.6 seconds. The Gerchberg-Saxton Algorithm is slightly faster than RAAR, because it does not take the intermediate data into account, so it has fewer calculations to execute. A GS implementation on the CPU needs for the same image size 15 seconds, this is a speed up of factor 25. A matlab implementation of GS needs for 30 iterations 17 seconds and for 30 steps of RAAR 22 seconds(CPU times: private communication by Hecke Degering). You can see in this table some more run time values (all values in seconds). Up to a certain point you can see no difference in the run time between GS and RAAR, but if you make more than 50 iterations, the additional operations in RAAR are noticeable.
| iterations | Gerchberg-Saxton | RAAR |
| 1 | 0.673 | 0.673 |
| 10 | 0.710 | 0.709 |
| 50 | 0.837 | 0.858 |
| 100 | 0.973 | 1.042 |
| 150 | 1.337 | 1.458 |
The SLM used in the experimental setup needs a minimum of 30 ms to change its configuration, because of the inertia of the liquid crystal. This is the timeframe for calculations. The algorithm works with this runtime values nearly in the timeframe, assumed that 30 iterations are enough to produce useful picture. The next generation of GPUs should be fast enough, so that the timeframe is not violated.
But there are also other criteria to judge the algorithms.
One can look for example at the root mean square error 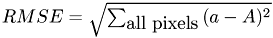 , with the current iterated intensity and the intensity in the original image, but this error is not suited for this problem, because it treats all aberrations in the same way. Aberrations for actual dark pixels are worse than aberrarations for illuminated pixels so we have to use an error measurement that takes this into account. The proposed error which has this properties looks like:
, with the current iterated intensity and the intensity in the original image, but this error is not suited for this problem, because it treats all aberrations in the same way. Aberrations for actual dark pixels are worse than aberrarations for illuminated pixels so we have to use an error measurement that takes this into account. The proposed error which has this properties looks like:
The total error is the sum of and .
This is the image used to create the plots:
In the experiment the white spots would be the positions of the neurons to stimulate.

Input image.
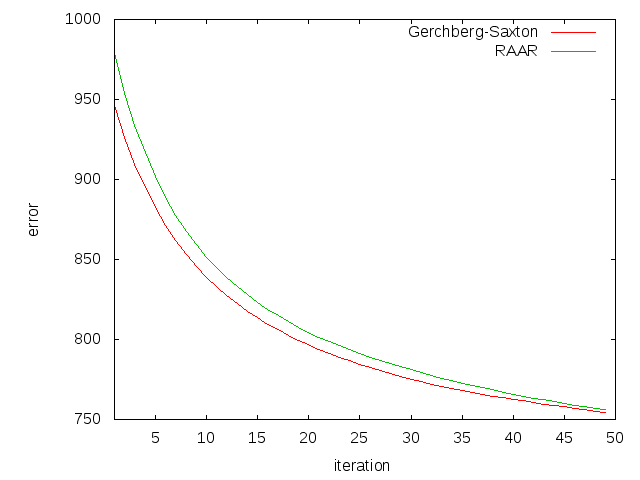
Error comparison for both algorithms.
Now we can look at the reconstructed pictures:
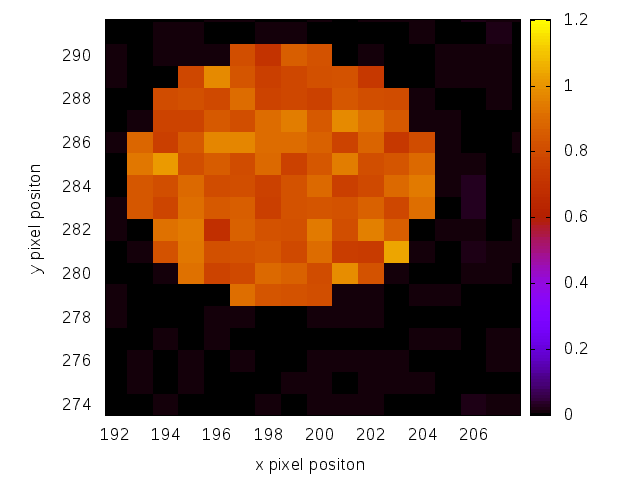
A reconstructed lightspot using GS.
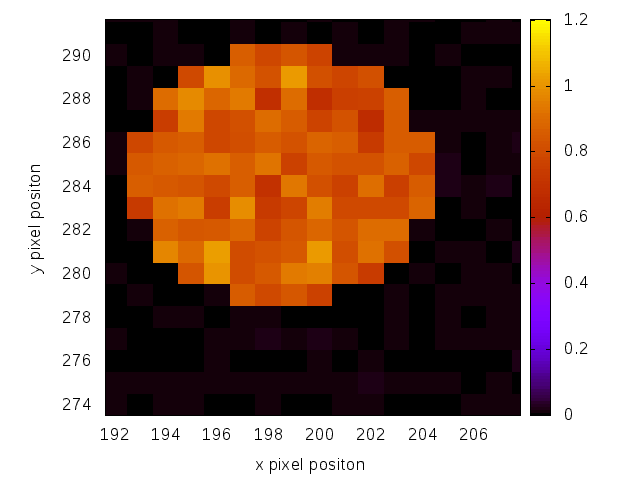
The same reconstructed lightspot using RAAR.
We can see, that both algorithms produce relative evenly illuminated dots. So we can assume, that neurons in this region will get excited.
Here is a dark region of the image:
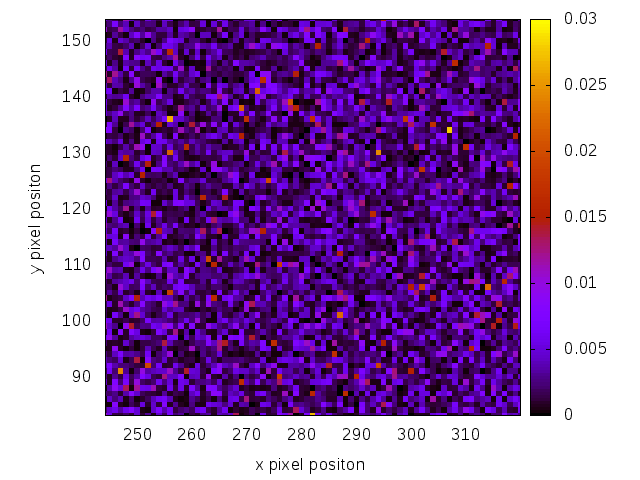
Dark region using GS.
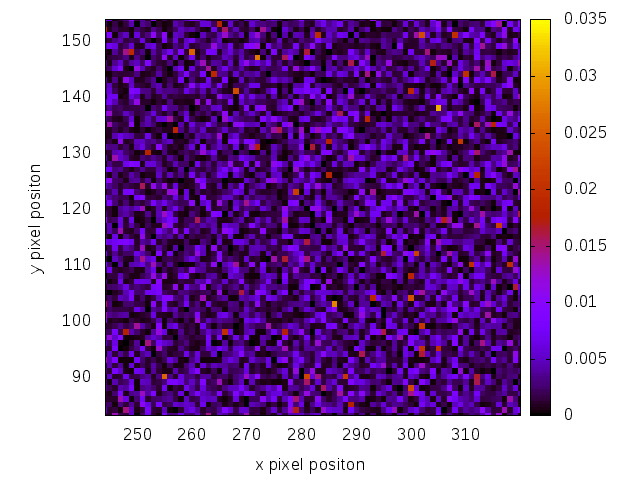
Dark region using RAAR .
But the dark regions are of bigger importance. You can see this in the error calculation. Dark pixels which are illuminated too much have a bigger contribution to the error.
Note, that the scales of both pictures differ slightly. We can see both algorithms produce comparable results. Actually RAAR should produce better dark regions than GS, but this depends on the input image.
This concludes the results. Possible points for further development are:
- GUI for simplified testing
- other algorithms (groundwork for other implementations is already done)
- OpenGL for direct integration in experiment (control of SLM via DVI)
- work on the error, to find out a general behaviour
The plain program
(If you are looking at a locally installed CUDA HPC Praktikum version, then the program can be found at .. /.. /testsite / /step-16 /step-cu.cc . Otherwise, this is only the path on some remote server.)
#ifndef CUDA_KERNEL_STEP_16_CU_H #define CUDA_KERNEL_STEP_16_CU_H #include <vector> template<typename T> struct CUDAPrecisionTraits; template <> struct CUDAPrecisionTraits<cuComplex> { typedef float NumberType; typedef cuComplex CudaComplex; }; template <> struct CUDAPrecisionTraits<cuDoubleComplex> { typedef double NumberType; typedef cuDoubleComplex CudaComplex; }; template <> struct CUDAPrecisionTraits<float> { typedef float NumberType; typedef cuComplex CudaComplex; }; template <> struct CUDAPrecisionTraits<double> { typedef double NumberType; typedef cuDoubleComplex CudaComplex; };
enum ParallelArch { cpu, gpu_cuda, gpu_opencl };
void amplitude_adaption_r(cufftComplex *d_devPtr, const cufftComplex *d_original, int size, int height, int width, ParallelArch arch); #ifndef USE_SINGLE_PRECISION void amplitude_adaption_r(cufftDoubleComplex *d_devPtr, cufftDoubleComplex *d_original, int size, int height, int width, ParallelArch arch); #endif void amplitude_adaption_f(cufftComplex *d_devPtr, int size, int sum, int height, int width, ParallelArch arch); #ifndef USE_SINGLE_PRECISION void amplitude_adaption_f(cufftDoubleComplex *d_devPtr, int size,int sum, int height, int width, ParallelArch arch); #endif void amplitude_adaption_rRAAR(cufftComplex *d_devPtr, const cufftComplex *d_original, int size, int height, int width, ParallelArch arch); #ifndef USE_SINGLE_PRECISION void amplitude_adaption_rRAAR(cufftDoubleComplex *d_devPtr, cufftDoubleComplex *d_original, int size, int height, int width, ParallelArch arch); #endif void amplitude_adaption_fRAAR(cufftComplex *d_devPtr, int size, int height, int width, int sum,ParallelArch arch); #ifndef USE_SINGLE_PRECISION void amplitude_adaption_fRAAR(cufftDoubleComplex *d_devPtr, int size, int height, int width, int sum, ParallelArch arch); #endif void rescale(cufftComplex *d_devPtr, int size, int height, int width, ParallelArch arch); #ifndef USE_SINGLE_PRECISION void rescale(cufftDoubleComplex *d_devPtr, int size, int height, int width, ParallelArch arch); #endif void twilight_error(cufftComplex *d_devPtr, const cufftComplex *d_original, cufftComplex *d_error, int size, int height, int width, ParallelArch arch); #ifndef USE_SINGLE_PRECISION void twilight_error(cufftDoubleComplex *d_devPtr, cufftDoubleComplex *d_original, cufftDoubleComplex *d_error, int size, int height, int width, ParallelArch arch); #endif void randomize(cufftComplex *d_devPtr, const float *d_rndnumbers, int size, int height, int width, ParallelArch arch); #ifndef USE_SINGLE_PRECISION void randomize(cufftDoubleComplex *d_devPtr, const double *d_rndnumbers, int size, int height, int width, ParallelArch arch); #endif #endif // CUDA_KERNEL_STEP_16_CU_H #include <cutil_inline.h> #include <cuda_kernel_wrapper_step-16.cu.h> #include <vector>
template <typename T> __host__ __device__ bool __is_zero(T x); __host__ __device__ bool __is_zero(double x) { if(x >= 2e-16) {return true;}/ *true and false were switched, now it looks unlogical, but i think its better* / else return false; } __host__ __device__ bool __is_zero(float x) { if(x >= 2e-8) {return true;} else return false; }
template <typename T> __host__ __device__ void __amplitude_adaption_r_element(T *d_devPtr, const T *d_original, int x) { typedef typename CUDAPrecisionTraits<T>::NumberType NumberType; NumberType real = d_devPtr[x].x; NumberType imag = d_devPtr[x].y; NumberType abs = sqrt(real*real+imag*imag); if(d_original[x].x==0) { d_devPtr[x].x=0; d_devPtr[x].y=0; } else { if( __is_zero(abs)) { real = (real/abs); imag = (imag/abs); } d_devPtr[x].x=real; d_devPtr[x].y=imag; } }
template <typename T> __global__ void __amplitude_adaption_r(T *d_devPtr, const T *d_original, int size) { int x = blockDim.x*blockIdx.x+threadIdx.x; if(x<size) __amplitude_adaption_r_element(d_devPtr,d_original,x); }
template<typename T> void _amplitude_adaption_r(T *d_devPtr, const T *d_original, int size, int height,int width, ParallelArch arch) { switch(arch) { case gpu_cuda: // gpu height = (size/512)+1; __amplitude_adaption_r<T><<<height,512>>>(d_devPtr, d_original,size); cudaThreadSynchronize(); break; case cpu: //cpu for(int i = 0;i < size;i++) {__amplitude_adaption_r_element<T>(d_devPtr, d_original, i); } break; case gpu_opencl: break; } } void amplitude_adaption_r(cufftComplex *d_devPtr, const cufftComplex *d_original, int size, int height, int width, ParallelArch arch) { _amplitude_adaption_r(d_devPtr, d_original, size, height, width, arch); } #ifndef USE_SINGLE_PRECISION void amplitude_adaption_r(cufftDoubleComplex *d_devPtr, const cufftDoubleComplex *d_original, int size, int height, int width, ParallelArch arch) { _amplitude_adaption_r(d_devPtr, d_original, size, height, width, arch); } #endif
template <typename T> __host__ __device__ void __amplitude_adaption_f_element(T *d_devPtr, int size, int sum, int x) { typedef typename CUDAPrecisionTraits<T>::NumberType NumberType; NumberType real = d_devPtr[x].x; NumberType imag = d_devPtr[x].y; real/=size; imag/=size; NumberType abs = sqrt(real*real+imag*imag); NumberType factor = sqrt(sum*1.0)/(size*1.0); if(__is_zero(abs)) { real = (real/abs)*factor; imag = (imag/abs)*factor; } else { real = 0; imag = 0; } d_devPtr[x].x=real; d_devPtr[x].y=imag; }
template <typename T> __global__ void __amplitude_adaption_f(T *d_devPtr, int size, int sum) { int x = blockDim.x*blockIdx.x+threadIdx.x; if(x<size) __amplitude_adaption_f_element(d_devPtr, size, sum, x); }
template<typename T> void _amplitude_adaption_f(T *d_devPtr, int size, int sum,int height, int width, ParallelArch arch) { switch(arch) { case gpu_cuda: height = (size/512)+1; __amplitude_adaption_f<T><<<height,512>>>(d_devPtr, size, sum); cudaThreadSynchronize(); break; case cpu: //cpu for(int i = 0;i < size;i++) {__amplitude_adaption_f_element<T>(d_devPtr,size ,sum, i); } break; case gpu_opencl: break; } } void amplitude_adaption_f(cufftComplex *d_devPtr,int sum, int size, int height, int width, ParallelArch arch) { _amplitude_adaption_f(d_devPtr,sum, size, height, width, arch); } #ifndef USE_SINGLE_PRECISION void amplitude_adaption_f(cufftDoubleComplex *d_devPtr,int sum, int size, int height, int width, ParallelArch arch) { _amplitude_adaption_f(d_devPtr, sum, size, height, width, arch); } #endif
template <typename T> __host__ __device__ void __rescale_element(T *d_devPtr, int size, int x) { d_devPtr[x].x/=size; d_devPtr[x].y/=size; }
template<typename T> __global__ void __rescale(T *d_devPtr, int size) { int x = blockDim.x*blockIdx.x+threadIdx.x; if(x<size) __rescale_element(d_devPtr, size, x); }
template<typename T> void _rescale(T *d_devPtr, int size, int height, int width, ParallelArch arch) { switch(arch) { case gpu_cuda: height = (size/512)+1; __rescale<T><<<height, width>>>(d_devPtr,size); cudaThreadSynchronize(); break; case cpu: for(int i = 0;i < size;i++) __rescale_element(d_devPtr, size, i); break; case gpu_opencl: break; } } void rescale(cufftComplex *d_devPtr, int size, int height, int width, ParallelArch arch) { _rescale(d_devPtr, size, height, width, arch); } #ifndef USE_SINGLE_PRECISION template<typename T> void rescale(cufftDoubleComplex *d_devPtr, int size, int height, int width, ParallelArch arch) { _rescale(d_devPtr, size, height, width, arch); } #endif
template <typename T> __host__ __device__ void __twilight_error_element(T *d_devPtr, const T *d_original, T *d_error, int x) { typedef typename CUDAPrecisionTraits<T>::NumberType NumberType; d_error[x].x = 0; d_error[x].y = 0; T a_ampl = d_devPtr[x]; NumberType abs_a = (a_ampl.x*a_ampl.x + a_ampl.y*a_ampl.y); T A_ampl = d_original[x]; NumberType abs_A = (A_ampl.x*A_ampl.x + A_ampl.y*A_ampl.y); NumberType t_light = 0.1; NumberType t_dark = 3.333e-4; NumberType err_light = (abs(abs_A-abs_a)/abs_A - t_light); NumberType err_dark = (abs_a-t_dark); if(A_ampl.x == 0) {//error for dark pixel if(err_dark>0) { d_error[x].x = err_dark; } } else {//error for light pixel if(err_light>0) { d_error[x].x= err_light*(t_dark/t_light); } } }
template <typename T> __global__ void __twilight_error(T *d_devPtr, const T *d_original, T *d_error, int size) { int x = blockDim.x*blockIdx.x+threadIdx.x; if(x<size) __twilight_error_element(d_devPtr, d_original, d_error, x); }
template <typename T> void _twilight_error(T *d_devPtr,const T *d_original,T *d_error, int size, int height, int width, ParallelArch arch ) { switch(arch) { case gpu_cuda: height = (size/512)+1; __twilight_error<T><<<height, width>>>(d_devPtr, d_original, d_error, size); cudaThreadSynchronize(); break; case cpu: //cpu for(int i = 0;i < size;i++) {__twilight_error_element<T>(d_devPtr, d_original, d_error, i); } break; case gpu_opencl: break; } }
void twilight_error(cufftComplex *d_devPtr, const cufftComplex *d_original, cufftComplex *d_error, int size, int height, int width, ParallelArch arch) { _twilight_error(d_devPtr, d_original,d_error, size, height, width,arch); } #ifndef USE_SINGLE_PRECISION void twilight_error(cufftDoubleComplex *d_devPtr, const cufftDoubleComplex *d_original, cufftDoubleComplex *d_error, int size, int height, int width, ParallelArch arch) { _twilight_error(d_devPtr, d_original, d_error, size, height, width, arch); } #endif
template <typename T> __host__ __device__ void __randomize_element( typename CUDAPrecisionTraits<T>::CudaComplex *d_devPtr, const T *d_rndnumbers, int x) { typedef typename CUDAPrecisionTraits<T>::NumberType NumberType; NumberType rnd = d_rndnumbers[x]*6.28318; NumberType real = cos(rnd); NumberType imag = sin(rnd); d_devPtr[x].x=real; d_devPtr[x].y=imag; }
template <typename T> __global__ void __randomize( typename CUDAPrecisionTraits<T>::CudaComplex *d_devPtr, const T *d_rndnumbers, int size) { int x = blockDim.x*blockIdx.x+threadIdx.x; if(x<size) __randomize_element(d_devPtr, d_rndnumbers, x); }
template <typename T> void _randomize(typename CUDAPrecisionTraits<T>::CudaComplex *d_devPtr,const T *d_rndnumbers, int size, int height, int width, ParallelArch arch) { switch(arch) { case gpu_cuda: height = (size/512)+1; __randomize<T><<<height, width>>>(d_devPtr, d_rndnumbers, size); cudaThreadSynchronize(); break; case cpu: //cpu for(int i = 0;i < size;i++) {__randomize_element<T>(d_devPtr, d_rndnumbers, i); } break; case gpu_opencl: break; } } void randomize(cufftComplex *d_devPtr,const float *d_rndnumbers, int size, int height, int width, ParallelArch arch) { _randomize(d_devPtr, d_rndnumbers, size, height, width, arch); } #ifndef USE_SINGLE_PRECISION void randomize(cufftDoubleComplex *d_devPtr,const double *d_rndnumbers, int size, int height, int width, ParallelArch arch) { _randomize(d_devPtr, d_rndnumbers, size, height, width, arch); } #endif
template <typename T> __host__ __device__ void __amplitude_adaption_rRAAR_element(T *d_devPtr, const T *d_original, int x) { typedef typename CUDAPrecisionTraits<T>::NumberType NumberType; NumberType real = d_devPtr[x].x; NumberType imag = d_devPtr[x].y; NumberType abs = sqrt(real*real+imag*imag); if(d_original[x].x==0) { d_devPtr[x].x=0; d_devPtr[x].y=0; } else { if( __is_zero(abs) ) { real = (real/abs); imag = (imag/abs); } d_devPtr[x].x=real; d_devPtr[x].y=imag; } }
template <typename T> __global__ void __amplitude_adaption_rRAAR(T *d_devPtr, const T *d_original, int size) { typedef typename CUDAPrecisionTraits<T>::NumberType NumberType; int x = blockDim.x*blockIdx.x+threadIdx.x; if(x<size) __amplitude_adaption_rRAAR_element(d_devPtr, d_original, x); }
template <typename T> void _amplitude_adaption_rRAAR(T *d_devPtr, const T *d_original, int size, int height,int width, ParallelArch arch) { switch(arch) { case gpu_cuda: height = (size/512)+1; __amplitude_adaption_rRAAR<T><<<height,width>>>(d_devPtr, d_original,size); cudaThreadSynchronize(); break; case cpu: //cpu for(int i = 0;i < size;i++) {__amplitude_adaption_rRAAR_element<T>(d_devPtr, d_original, i); } break; case gpu_opencl: break; } } void amplitude_adaption_rRAAR(cufftComplex *d_devPtr, const cufftComplex *d_original, int size, int height, int width, ParallelArch arch) { _amplitude_adaption_rRAAR(d_devPtr,d_original,size, height, width,arch); } #ifndef USE_SINGLE_PRECISION void amplitude_adaption_rRAAR(cufftDoubleComplex *d_devPtr, const cufftDoubleComplex *d_original, int size, int height, int width, ParallelArch arch) { _amplitude_adaption_rRAAR(d_devPtr,d_original,size, height, width,arch); } #endif
template <typename T> __host__ __device__ void __amplitude_adaption_fRAAR_element(T *d_devPtr, int size,int sum, int x) { typedef typename CUDAPrecisionTraits<T>::NumberType NumberType; NumberType real = d_devPtr[x].x; NumberType imag = d_devPtr[x].y; real/=size; imag/=size; NumberType abs = sqrt(real*real+imag*imag); NumberType factor = sqrt(sum*1.0)/(size*1.0); if( __is_zero(abs) ) { real = (real/abs)*factor; imag = (imag/abs)*factor; } else { real = 0; imag = 0; } d_devPtr[x].x=real; d_devPtr[x].y=imag; }
template <typename T> __global__ void __amplitude_adaption_fRAAR(T *d_devPtr, int size,int sum) { int x = blockDim.x*blockIdx.x+threadIdx.x; if(x<size) __amplitude_adaption_fRAAR_element(d_devPtr, size, sum,x); }
template<typename T> void _amplitude_adaption_fRAAR(T *d_devPtr, int size, int sum,int height, int width, ParallelArch arch) { switch(arch) { case gpu_cuda: height = (size/512)+1; __amplitude_adaption_fRAAR<T><<<height, width>>>(d_devPtr,size,sum); cudaThreadSynchronize(); break; case cpu: for(int i = 0;i < size;i++) {__amplitude_adaption_fRAAR_element<T>(d_devPtr,size ,sum ,i); } break; case gpu_opencl: break; } } void amplitude_adaption_fRAAR(cufftComplex *d_devPtr,int size, int sum, int height, int width, ParallelArch arch) { _amplitude_adaption_fRAAR(d_devPtr,size, sum, height, width, arch); } #ifndef USE_SINGLE_PRECISION void amplitude_adaption_fRAAR(cufftDoubleComplex *d_devPtr,int size, int sum, int height, int width, ParallelArch arch) { _amplitude_adaption_fRAAR(d_devPtr,size, sum, height, width, arch); } #endif
#ifndef CUDADriver_STEP_16_H #define CUDADriver_STEP_16_H #include <lac/blas++.h> #include <vector> #include <string> #include <sstream> #include <base/parameter_handler.h> using namespace std; namespace step16 { template<typename T> struct VTraits { typedef typename PrecisionTraits<T>::NumberType NumberType; typedef typename PrecisionTraits<T>::CudaComplex CudaComplex; typedef typename blas_pp<CudaComplex, cublas>::Vector FFTVector; typedef std::vector<CudaComplex> ImageVector; }; class Parameters { public: static void declare(::ParameterHandler & prm); void get(::ParameterHandler & prm); Parameters(){} stringstream filename; stringstream outputfolder; stringstream append; int iterations; int algorithm; int realisations; private: Parameters(const Parameters & ) {} Parameters & operator = (const Parameters & / *other* /) { return *this; } };
template<typename T> class Image : public VTraits<T>::ImageVector { public: typedef typename VTraits<T>::ImageVector Base; typedef typename VTraits<T>::FFTVector FFTVector; typedef typename VTraits<T>::CudaComplex CudaComplex; typedef typename FFTVector::blas_wrapper_type BW; Image() {} Image(QImage img); int width; int height; int sum; Image & operator = (const FFTVector& / *src* /); Image & operator = (const Image<T>& other) { width = other.width; height = other.height; sum = other.sum; Base & self = *this; self = other; return *this; } Image(const Image<T>& other) { *this = other; } private: };
template <typename T> class CUDAPhaseHologramDriver { public: typedef typename VTraits<T>::NumberType NumberType; typedef typename VTraits<T>::FFTVector FFTVector; typedef typename VTraits<T>::CudaComplex CudaComplex; typedef typename FFTVector::blas_wrapper_type BW; CUDAPhaseHologramDriver(int iterations, Image<T> &image, Image<T> &ftimage, std::vector<double> &error, std::vector<Image<T> > &iterationsteps); ~CUDAPhaseHologramDriver (); void compute(); void computeRAAR(); void computeRAAR2(); const FFTVector & get_d_image() const ; private: int iterations; Image<T> * image; Image<T> * ftimage; FFTVector d_image; FFTVector d_original; int size; int width; int height; int sum; std::vector<double> &errorout; std::vector<Image<T> > &iterationsteps; }; template<cufftType_t cufft_type> struct FFTTraits; template<> struct FFTTraits<CUFFT_C2C> { typedef cuComplex T_dst; typedef cuComplex T_src; static cufftResult exec(cufftHandle &plan, cufftComplex *dst, cufftComplex *src, int direction) { return cufftExecC2C(plan, src, dst, direction); } }; template<> struct FFTTraits<CUFFT_R2C> { typedef float T_dst; typedef cuComplex T_src; static cufftResult exec(cufftHandle &plan, cufftComplex *dst, cufftReal *src, int / *direction* /) { return cufftExecR2C(plan, src, dst); } }; template<> struct FFTTraits<CUFFT_C2R> { typedef float T_dst; typedef cuComplex T_src; static cufftResult exec(cufftHandle &plan, cufftReal *dst, cufftComplex *src, int / *direction* /) { return cufftExecC2R(plan, src, dst); } }; template<> struct FFTTraits<CUFFT_Z2Z> { typedef cuDoubleComplex T_dst; typedef cuDoubleComplex T_src; static cufftResult exec(cufftHandle &plan, cufftDoubleComplex *dst, cufftDoubleComplex *src, int direction) { return cufftExecZ2Z(plan, src, dst, direction); } }; template<> struct FFTTraits<CUFFT_D2Z> { typedef cuDoubleComplex T_dst; typedef double T_src; static cufftResult exec(cufftHandle &plan, cufftDoubleComplex *dst, cufftDoubleReal *src, int / *direction* /) { return cufftExecD2Z(plan, src, dst); } }; template<> struct FFTTraits<CUFFT_Z2D> { typedef double T_dst; typedef cuDoubleComplex T_src; static cufftResult exec(cufftHandle &plan, cufftDoubleReal *dst, cufftDoubleComplex *src, int / *direction* /) { return cufftExecZ2D(plan, src, dst); } }; template <int d, cufftType_t cufft_type, bool inv> class CUDAFFT { public: static const int dim = d; static const cufftType_t variant = cufft_type; static const bool inverse = inv; typedef typename FFTTraits<cufft_type>::T_dst T_dst; typedef typename FFTTraits<cufft_type>::T_src T_src; typedef typename VTraits<T_dst>::FFTVector FFTVectorDST; typedef typename VTraits<T_src>::FFTVector FFTVectorSRC; CUDAFFT(); ~CUDAFFT(); void operator() (FFTVectorDST *dst, FFTVectorSRC *src, int width, int height); cufftHandle plan; private: }; template <typename T> class CUDArnd { public: typedef typename VTraits<T>::NumberType NumberType; typedef typename VTraits<T>::FFTVector FFTVector; private: }; } // namespace step16 END #endif // CUDADriver_STEP_16_H
#ifndef CUDA_DRIVER_STEP_16_HH #define CUDA_DRIVER_STEP_16_HH #include "cuda_driver_step-16.h" #include "cuda_kernel_wrapper_step-16.cu.h" #include <cutil_inline.h>
void step16::Parameters::declare(::ParameterHandler & prm) { prm.enter_subsection("Dimensions of test problems."); prm.declare_entry ("iterations", "20", ::Patterns::Integer(), "Number of iterations"); prm.declare_entry ("input file", "pattern.bmp", ::Patterns::Anything(), "Name of bmp input file"); prm.declare_entry ("output folder", "./results/", ::Patterns::Anything(), "Ouputfolder for results, form ./foldername/"); prm.declare_entry("algorithm", "1", ::Patterns::Integer(), "Choose algorithm:\n" "1: Gerchberg Saxton\n" "2: RAAR"); prm.declare_entry("apendix", "", ::Patterns::Anything(), "append something to your output file names"); prm.declare_entry ("realisations", "20", ::Patterns::Integer(), "Number of realisations"); prm.leave_subsection(); }
void step16::Parameters::get(::ParameterHandler & prm) { prm.enter_subsection("Dimensions of test problems."); iterations = prm.get_integer ("iterations") ; filename.str(prm.get ("input file")) ; outputfolder.str(prm.get("output folder")); algorithm = prm.get_integer("algorithm"); append.str(prm.get("apendix")); realisations = prm.get_integer ("realisations") ; prm.leave_subsection(); }
template<typename T> step16::Image<T>::Image(QImage img) : Base(), width(img.width()), height(img.height()), sum(0) { this->resize( width*height); for(int i=0;i< height;i++) { for(int j=0;j< width;j++) { QColor c = QColor::fromRgb (img.pixel(j,i) ); if (c == Qt::white) { (*this)[i*height+j].x = 1.0; //realpart (*this)[i*height+j].y = 0.0; //imag part sum++; } else if (c == Qt::black) { (*this)[i*height+j].x = 0.0; (*this)[i*height+j].y = 0.0; } } } std::cout <<"host: width:"<<(*this).width <<" height:"<<(*this).height <<" size:"<<(*this).size()<< std::endl; }
template<typename T> step16::Image<T> & step16::Image<T>::operator = (const / *step16::* /FFTVector& src) { if (this->size() != src.size()) this->resize(src.size()); CudaComplex * dst_ptr = &(*this)[0]; const CudaComplex * src_ptr = src.array().val(); #ifdef DEBUG std::cout << "src n_pixels : " << src.size() << " dst n_pixels : " << this->size() << std::endl; #endif BW::GetVector(this->size(), src_ptr, 1, dst_ptr, 1); return *this; }
template <typename T> step16::CUDAPhaseHologramDriver<T>:: CUDAPhaseHologramDriver(int _iterations, Image<T> &_image, Image<T> &_ftimage, std::vector<double> &_error, std::vector<Image<T> > &_iterationsteps) : iterations(_iterations), image(&_image), ftimage(&_ftimage), size(_image.size()), width(_image.width), height(_image.height), sum(_image.sum), errorout(_error), iterationsteps(_iterationsteps) { errorout.resize(iterations); iterationsteps.resize(iterations); BW::Init(); cudaThreadSynchronize(); d_image.reinit(_image.size() ); d_image = _image; d_original.reinit(_image.size() ); d_original = d_image; std::cout<<"device: width:"<<width<<" height:"<<height <<" size:"<<size<< std::endl; }
template<typename T> step16::CUDAPhaseHologramDriver<T>::~CUDAPhaseHologramDriver() { BW::Shutdown(); image = NULL; ftimage = NULL; }
template<typename T> void step16::CUDAPhaseHologramDriver<T>::compute() { ParallelArch arch = gpu_cuda; CUDAFFT<2,CUFFT_C2C,false> FFT_forward; cufftHandle plan; cufftPlan2d(&plan, width ,height ,CUFFT_C2C); for(int i=0;i<iterations;i++) { //FFT_forward(d_image.array().val(),d_image.array().val(),width,height); cufftExecC2C(plan, d_image.array().val(), d_image.array().val(), CUFFT_FORWARD); cudaThreadSynchronize(); amplitude_adaption_f(d_image.array().val(), size, sum, height,width, arch); cudaThreadSynchronize(); cufftExecC2C(plan, d_image.array().val(), d_image.array().val(), CUFFT_INVERSE); cudaThreadSynchronize(); / *cuComplex zero; zero.x = 0.; zero.y = 0.; FFTVector error(d_image.size()); error *= zero; error = d_image; error = d_original; error = d_image; error -= d_original; errorout[i]=error.l2_norm().x; * / FFTVector d_error(size); twilight_error(d_image.array().val(), d_original.array().val(), d_error.array().val(), size,height,width,arch); cudaThreadSynchronize(); errorout[i] = d_error.sum(); iterationsteps[i] = d_image; amplitude_adaption_r(d_image.array().val(),d_original.array().val(),size, height,width,arch); cudaThreadSynchronize(); } cufftExecC2C(plan, d_image.array().val(), d_image.array().val(), CUFFT_FORWARD); cudaThreadSynchronize(); FFTVector d_copy; d_copy = d_image; rescale(d_copy.array().val(),size,height,width, arch); cudaThreadSynchronize(); (*ftimage) = d_copy; (*ftimage).width = width; (*ftimage).height = height; amplitude_adaption_f(d_image.array().val(),size,sum,height,width, arch); cudaThreadSynchronize(); cufftExecC2C(plan, d_image.array().val(),d_image.array().val(), CUFFT_INVERSE); cudaThreadSynchronize(); (*image) = d_image; cufftDestroy(plan); } template<typename T> void step16::CUDAPhaseHologramDriver<T>::computeRAAR() { ParallelArch arch = gpu_cuda; FFTVector d_copy; cufftHandle plan; cufftPlan2d(&plan, width ,height ,CUFFT_C2C); for(int i=0;i<iterations;i++) { cout<<"iteration:"<<i<<endl; d_copy = d_image; FFTVector tmp; FFTVector tmp2; float beta_0 = 0.75; float beta_max = 0.99; float beta = 0; int i_switch = 3.0; float factor = exp(pow(-i*1.0/i_switch,3.0)); beta = beta_0*factor + beta_max*(1 - factor); cout<<"beta:"<<beta<<endl; cufftExecC2C(plan, d_image.array().val(), d_image.array().val(), CUFFT_FORWARD); cudaThreadSynchronize(); amplitude_adaption_f(d_image.array().val(),size,sum,height, width, arch); cudaThreadSynchronize(); cufftExecC2C(plan, d_image.array().val(), d_image.array().val(), CUFFT_INVERSE); cudaThreadSynchronize(); / *cuComplex zero; zero.x = 0.; zero.y = 0.; FFTVector error(d_image.size()); error *= zero; error = d_image; error = d_original; error = d_image; error -= d_original; errorout[i]=error.l2_norm().x; * / FFTVector d_error(size); twilight_error(d_image.array().val(),d_original.array().val(),d_error.array().val(), size,height,width, arch); cudaThreadSynchronize(); errorout[i] = d_error.sum(); iterationsteps[i] = d_image; tmp2 = d_image; amplitude_adaption_r(d_image.array().val(),d_original.array().val(),size, height,width,arch); cudaThreadSynchronize(); cuComplex factor2; factor2.x = 2.0; factor2.y = 0.0; d_image*=factor2; tmp = d_copy; amplitude_adaption_r(tmp.array().val(),d_original.array().val(),size,height, width,arch); d_image-=tmp; d_image-=tmp2; d_image+= d_copy; factor2.x = beta; d_image *= factor2; factor2.x=0.5*(1.0-beta); tmp2 *= factor2; d_image+=tmp2; } cufftExecC2C(plan, d_image.array().val(), d_image.array().val(), CUFFT_FORWARD); cudaThreadSynchronize(); d_copy = d_image; rescale(d_copy.array().val(),size,height,width,arch); cudaThreadSynchronize(); (*ftimage) = d_copy; (*ftimage).width = width; (*ftimage).height = height; amplitude_adaption_f(d_image.array().val(),size,sum,height,width,arch); cudaThreadSynchronize(); cufftExecC2C(plan, d_image.array().val(),d_image.array().val(), CUFFT_INVERSE); cudaThreadSynchronize(); (*image) = d_image; cufftDestroy(plan); } template<typename T> void step16::CUDAPhaseHologramDriver<T>::computeRAAR2() { ParallelArch arch = gpu_cuda; typename blas_pp<NumberType, cublas>::Vector d_rnd(size); FFTVector d_copy; cufftHandle plan; cufftPlan2d(&plan, width ,height ,CUFFT_C2C); for(int i=0;i<iterations;i++) { //cout<<"iteration:"<<i<<endl; d_copy = d_image; FFTVector tmp; FFTVector tmp2; float beta_0 = 0.75; float beta_max = 0.99; float beta = 0; int i_switch = 3.0; float factor = exp(pow(-i*1.0/i_switch,3.0)); beta = beta_0*factor + beta_max*(1 - factor); cufftExecC2C(plan, d_image.array().val(), d_image.array().val(), CUFFT_FORWARD); cudaThreadSynchronize(); FFTVector d_error(size); twilighterror(d_image.array().val(),d_original.array().val(),d_error.array().val(), errorout,size,height,width,i); cudaThreadSynchronize(); errorout[i] = d_error.sum(); iterationsteps[i] = d_image; amplitude_adaption_r(d_image.array().val(),d_original.array().val(),size, height,width); cudaThreadSynchronize(); cufftExecC2C(plan, d_image.array().val(), d_image.array().val(), CUFFT_INVERSE); cudaThreadSynchronize(); tmp2 = d_image; amplitude_adaption_f(d_image.array().val(),size,sum,height,width); cudaThreadSynchronize(); cuComplex factor2; factor2.x = 2.0; factor2.y = 0.0; d_image*=factor2; tmp = d_copy; amplitude_adaption_f(tmp.array().val(), size, sum, height,width); d_image-=tmp; d_image-=tmp2; d_image+= d_copy; factor2.x = beta; d_image *= factor2; factor2.x=0.5*(1.0-beta); tmp2 *= factor2; d_image+=tmp2; } (*ftimage) = d_image; (*ftimage).width = width; (*ftimage).height = height; cufftExecC2C(plan, d_image.array().val(), d_image.array().val(), CUFFT_FORWARD); cudaThreadSynchronize(); rescale(d_image.array().val(),size,height,width, arch); cudaThreadSynchronize(); (*image) = d_image; cufftDestroy(plan); }
template <typename T> const typename step16::CUDAPhaseHologramDriver<T>::FFTVector & step16::CUDAPhaseHologramDriver<T>::get_d_image() const { return this->d_image; }
template<int dim, cufftType_t cufft_type, bool inverse> step16::CUDAFFT< dim, cufft_type,inverse>::CUDAFFT() {}
template < int dim, cufftType_t cufft_type, bool inverse> step16::CUDAFFT<dim, cufft_type, inverse>::~CUDAFFT() { cufftDestroy(plan); }
template <int dim, cufftType_t cufft_type, bool inverse> void step16::CUDAFFT<dim, cufft_type, inverse>::operator() (FFTVectorDST * dst, FFTVectorSRC * src, int width, int height) { switch(dim) { case 1: cufftPlan1d(&plan, width , cufft_type,1); case 2: cufftPlan2d(&plan, width ,height ,cufft_type); break; case 3: default: break; } cufftResult result = FFTTraits<cufft_type>::exec(plan, dst.array().val(), src.array().val(), (inverse ? CUFFT_INVERSE : CUFFT_FORWARD) ); cudaThreadSynchronize(); if(result!=CUFFT_SUCCESS) { switch(result) { case CUFFT_INVALID_PLAN: std::cout<<"CUFFT is passed an invalid plan handle."<<std::endl; case CUFFT_ALLOC_FAILED: std::cout<<"CUFFT failed to allocate GPU memory."<<std::endl; case CUFFT_INVALID_TYPE: std::cout<<"The user requests an unsupported type."<<std::endl; case CUFFT_INVALID_VALUE: std::cout<<"The user specifies a bad memory pointer."<<std::endl; case CUFFT_INTERNAL_ERROR: std::cout<<"Internal driver errors."<<std::endl; case CUFFT_EXEC_FAILED: std::cout<<"CUFFT failed to execute an FFT on the GPU."<<std::endl; case CUFFT_SETUP_FAILED: std::cout<<"The CUFFT library failed to initialize."<<std::endl; case CUFFT_INVALID_SIZE: std::cout<<"The user specifies an unsupported FFT size."<<std::endl; case CUFFT_UNALIGNED_DATA: std::cout<<"Input or output does not satisfy texture alignment requirements."<<std::endl; } } } #endif // CUDA_DRIVER_STEP_16_HH #include "step-16.hh" using namespace std;
int main(int / *argc* /, char *argv[]) { using namespace step16; ::ParameterHandler prm_handler; Parameters::declare(prm_handler); std::string prm_filename(argv[0]); prm_filename += "-hologram.prm"; prm_handler.read_input (prm_filename); Parameters param; param.get(prm_handler); / *prm_filename += ".log"; std::ofstream log_out_text(prm_filename.c_str()); prm_handler.print_parameters (log_out_text, ::ParameterHandler::Text);* / MyFancySimulation<float> machma(param); machma.run(); machma.output(); }